LLM评估框架模块建立了多维度、全覆盖的大模型评估生态系统,涵盖通用能力测评、RAG系统评估和隐私安全检测。权威评测平台:CLiB中文大模型榜单(128个模型全覆盖,包含ChatGPT、GPT-4o、Gemini、文心一言、通义千问等商用模型,以及Qwen2.5、Llama3.1、GLM4、InternLM2.5等开源模型)、OpenCompass司南(全方位能力评估)、魔塔EvalScope(流水线式评测框架)。
RAG专项评估:RAGas(RAG Assessment专业框架)、Arize Phoenix(AI可观测性与评估)、DeepEval(LLM评估框架)、ChainForge(Prompt对战测试)等。多模态评估集成谷歌LMEval跨模型评估框架。隐私安全提供微软Presidio(PII敏感数据检测、编辑、掩码和匿名化),支持文本、图像和结构化数据的全方位隐私保护,确保模型应用的合规性和安全性。
- 1.CLiB中文大模型能力评测榜单
- 1.opencompass司南
- 2.魔塔evalscope
- 3.1.Arize Phoenix
- 3.1.DeepEval
- 3.1.RAGas(RAG Assessment)
- 3.RAG评估框架
- 4.多模态AI评估框架-谷歌
- 5.PII隐私保护
1.CLiB中文大模型能力评测榜单
简介
ReLE(Really Reliable Live Evaluation for LLM)是一个中文大模型能力评测项目,原名CLiB。目前已涵盖257个大模型,包括商用和开源模型。支持多维度能力评测,涉及医疗、教育等8个领域及约300个细分维度,提供排行榜和超200万的大模型缺陷库,还为私有大模型提供免费评测服务。
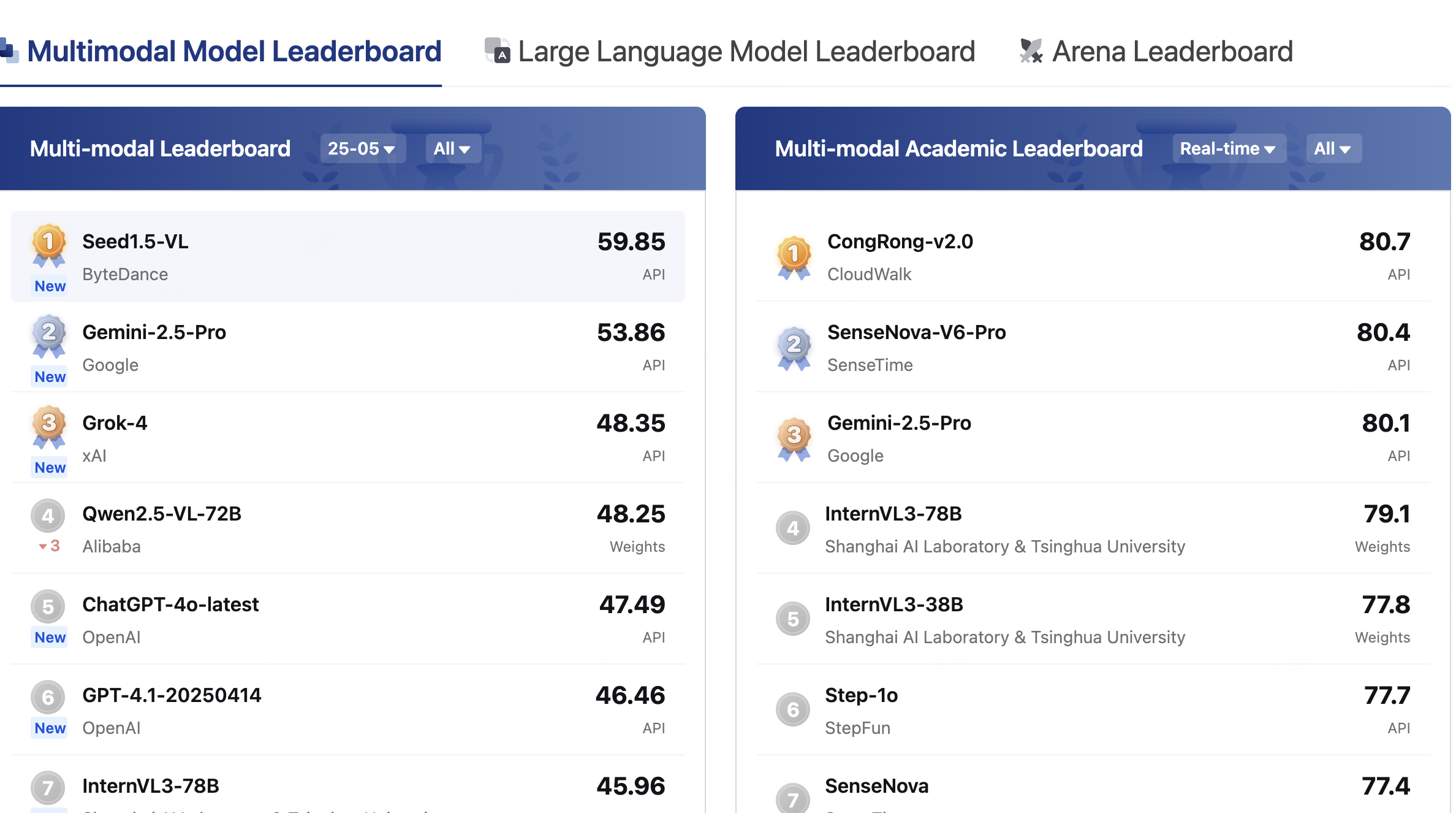
核心功能
- 对257个大模型进行多维度能力评测。
- 提供综合能力、推理类、各领域等多种排行榜。
- 构建规模超200万的大模型缺陷库。
- 为私有大模型提供免费评测服务。
应用场景
大模型开发者:分析大模型缺陷,改进模型性能。
企业或机构:选型合适的大模型。
研究人员:进行大模型相关的研究分析。
1.opencompass司南
简介
OpenCompass是面向大模型评测的一站式平台,提供丰富算法和功能支持,能帮助社区便捷、公平、全面地评估NLP模型性能,已被Meta AI官方推荐。
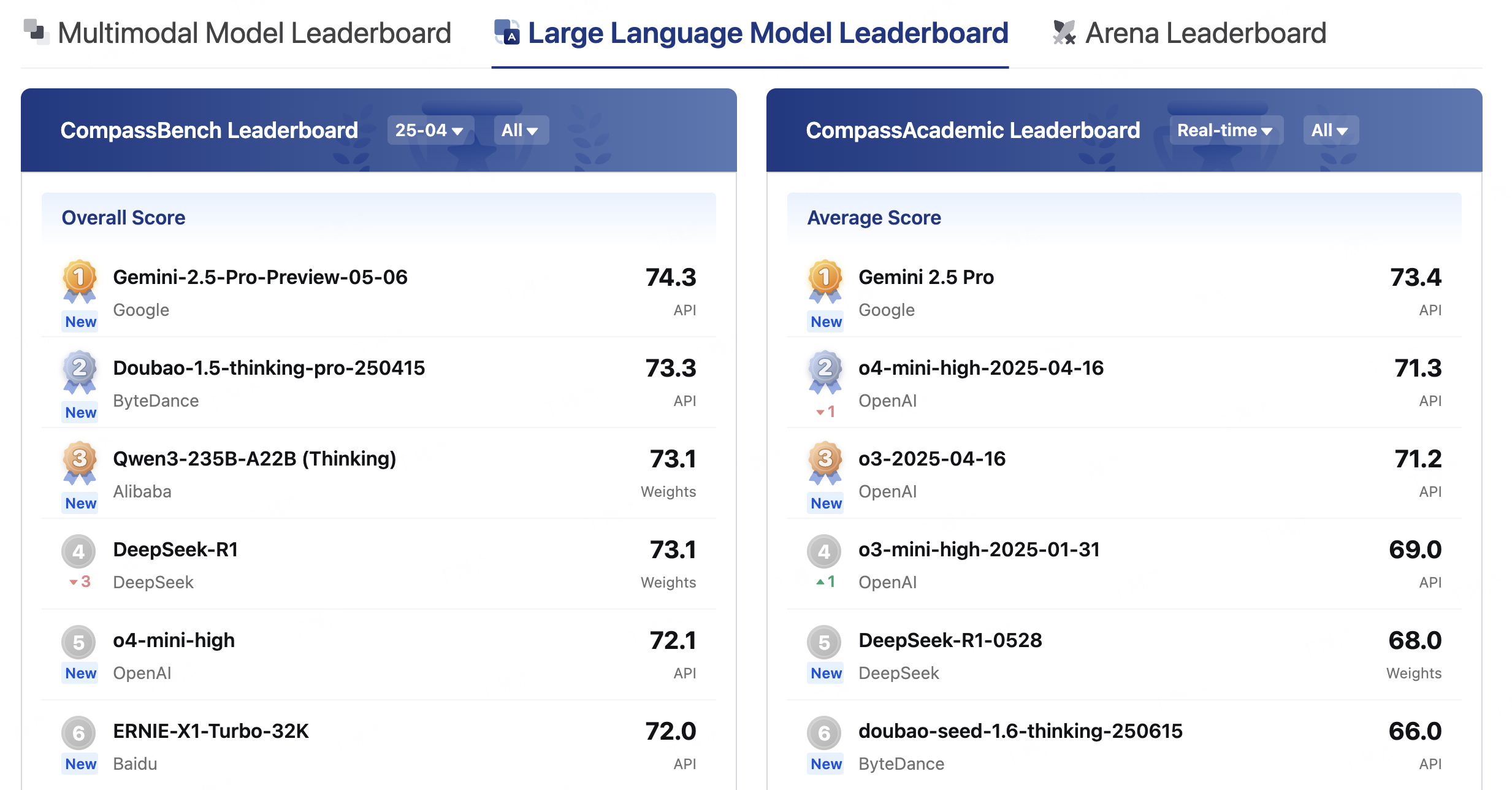
核心功能
- 模型评估:支持开源及API模型,可通过命令行或Python脚本配置,对多种模型在不同数据集上进行评估。
- 多范式评测:支持零样本、小样本及思维链评测,结合不同提示词模板激发模型性能。
- 分布式评测:一行命令实现任务分割和分布式评测,高效完成千亿模型全量评测。
- 灵活拓展:可轻松增加新模型、数据集,自定义任务分割策略,接入新集群管理系统。
技术原理
OpenCompass提供丰富的配置文件和工具,支持基于规则和LLM Judge的推荐配置,利用分布式计算技术实现高效评测。对于支持Huggingface AutoModel类或OpenAI接口推理引擎封装的模型,可直接进行评估。
应用场景
模型研发:研发人员可利用其全面评估模型能力,优化模型性能。
学术研究:为学术研究提供公平、可复现的评测方案,助力研究成果产出。
行业评测:企业可使用其对不同模型进行评测,选择合适的模型应用于业务。
opencompass测评/README_zh-CN.md at main · open-compass/opencompass
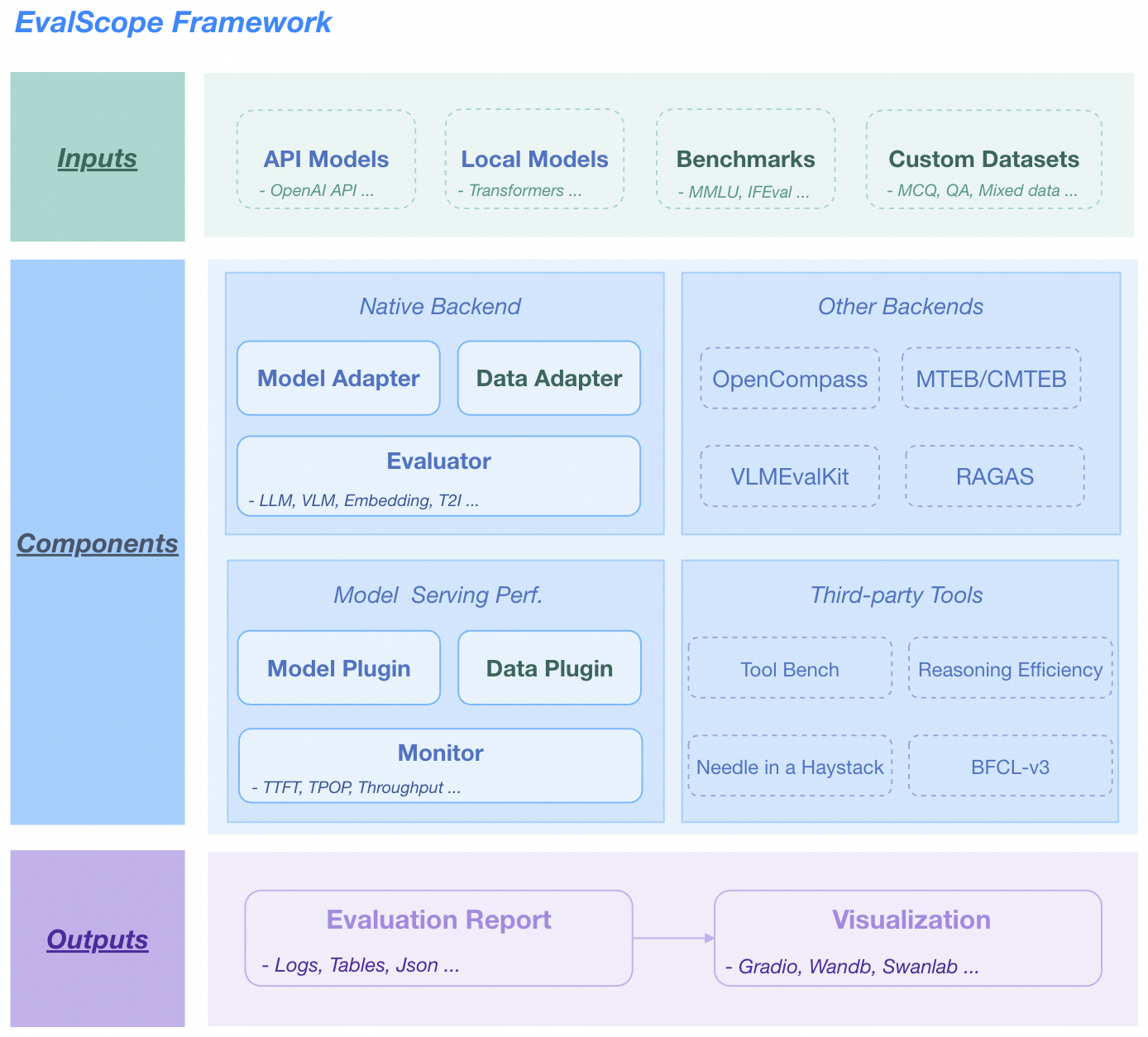
2.魔塔evalscope
简介
EvalScope 是由 ModelScope 社区精心打造的综合模型评估与性能基准测试框架,为模型评估提供一站式解决方案,可满足大语言模型、多模态模型、嵌入模型等多种类型模型的评估需求,集成多个行业认可的基准和评估指标,能进行模型推理性能压力测试,还可与 ms - swift 训练框架无缝集成。
核心功能
- 支持多种模型类型评估,如大语言模型、多模态模型等。
- 具备多个行业认可的基准和评估指标,如 MMLU、CMMLU 等。
- 可进行模型推理性能压力测试。
- 无缝集成 ms - swift 训练框架,实现一键评估。
- 支持可视化评估结果,方便对比不同模型性能。
- 提供多种评估模式,如单模型评估、竞技场模式、基线模型比较模式等。
- 支持自定义参数评估和自定义数据集评估。
技术原理
EvalScope 架构包含多个模块:
- 模型适配器:将特定模型输出转换为框架所需格式,支持 API 调用模型和本地运行模型。
- 数据适配器:对输入数据进行转换和处理,满足不同评估需求和格式。
- 评估后端:包括原生评估框架、OpenCompass、VLMEvalKit、RAGEval 和第三方评估任务等,支持多种评估模式和任务。
- 性能评估器:测量模型推理服务性能,包括性能测试、压力测试、报告生成和可视化。
- 评估报告:总结模型性能,用于决策和模型优化。
- 可视化:直观展示评估结果,便于分析和比较。
应用场景
- 模型开发者对大语言模型、多模态模型等进行性能评估和优化。
- 研究机构进行模型性能对比和基准测试。
- 企业在模型选型时,对不同模型进行评估和筛选。
- modelscope/eval-scope: A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
- modelscope/evalscope: A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
1.Arize Phoenix
简介
Arize Phoenix是一个开源的AI可观测性平台,具有隐私性和可定制性,可自行托管或通过免费云实例访问。它基于OpenTelemetry协议,功能全面,涵盖追踪、评估、实验等,与超20个框架集成,对所有集成一视同仁。此外,针对高级需求组织,Arize还提供企业级平台。
核心功能
- 追踪:深入洞察系统行为。
- 评估:衡量和优化模型性能。
- 实验:测试和比较不同方法。
- 数据集管理:简化数据集处理。
- 快速迭代:支持LLM提示优化和管理。
技术原理
由OpenTelemetry协议提供支持,该协议是经过实战检验的行业标准可观测性库,能使为Phoenix编写的代码在数十个其他平台上重复使用。
应用场景
适用于构建、评估和量产LLM应用程序的场景,可帮助用户在不同开发流程中对模型进行观测和优化。
1.DeepEval
简介
涉及三款与大语言模型(LLM)相关的工具。DeepEval 是开源的 LLM 评估框架,支持“单元测试”LLM 输出、使用多种评估指标、生成合成数据集、红队测试及实时评估等,还有配套云平台 Confident AI。Phoenix 是开源 AI 可观测性平台,提供追踪、评估、数据集管理、实验、 playground、提示管理等功能,支持多框架和 LLM 提供商,可在多环境运行。
核心功能
- DeepEval:提供 14 + 评估指标,支持自定义指标;可红队测试 LLM 应用安全漏洞;批量评估数据集;集成 CI/CD 环境;与 Confident AI 集成,实现持续评估、结果分析和数据集管理。
- Confident AI:数据持久化,支持回归测试、生成可共享测试报告、监控 LLM 输出、收集人类反馈。
- Phoenix:基于 OpenTelemetry 追踪 LLM 应用运行时;利用 LLMs 进行性能基准测试;创建版本化数据集;跟踪和评估提示、LLM 和检索的变化;优化提示、比较模型;系统管理和测试提示更改。
技术原理
- DeepEval:利用多种 NLP 模型和统计方法本地评估 LLM 输出,基于研究成果实现评估指标;通过继承基类创建自定义指标;利用进化技术生成合成数据集。
- Confident AI:与 DeepEval 自动集成,通过 API 实现评估结果记录、指标分析、实时监控和反馈收集。
- Phoenix:基于 OpenTelemetry 实现追踪功能;使用 LLMs 进行性能评估;通过版本控制管理数据集和提示。
应用场景
模型开发与优化:使用 DeepEval 和 Phoenix 评估模型输出,调整超参数,优化 RAG 管道和提示模板。
安全测试:利用 DeepEval 的红队测试功能,检测 LLM 应用安全漏洞。
持续监控:通过 Confident AI 和 Phoenix 实时监控 LLM 输出,及时发现问题。
团队协作:在 Confident AI 上管理评估数据集,方便团队成员协作。
Quick Introduction | DeepEval - The Open-Source LLM Evaluation Framework
1.RAGas(RAG Assessment)
简介
Ragas (RAG Assessment) 是一个开源框架,专为评估检索增强生成 (RAG) 管道及其他大型语言模型 (LLM) 应用程序而设计。它旨在帮助开发者量化其LLM应用的性能,提供客观的评估指标和数据驱动的洞察,从而简化和提升LLM应用(特别是RAG系统)的测试和改进过程。
核心功能
- RAG 管道评估: 提供一套全面的工具和指标,用于评估RAG系统在回答准确性、检索效率和上下文相关性方面的表现。
- LLM 应用评估: 不仅限于RAG,也支持对通用LLM应用进行评估,帮助识别其优缺点。
- 指标体系: 提供如忠实度 (Faithfulness)、答案相关性 (Answer Relevance)、上下文召回率 (Context Recall) 和上下文精确度 (Context Precision) 等多种专门指标,以量化RAG系统的各个方面。
- 合成测试数据生成: 能够生成高质量的合成测试数据,解决真实评估数据不足的问题,从而更有效地进行系统测试。
- 洞察与改进: 通过详细的评估报告,提供关于应用表现的深入洞察,帮助用户定位问题并有针对性地进行优化和改进。
技术原理
Ragas 的核心技术原理在于其指标驱动的评估方法。它通过定义和计算一系列专门针对RAG和LLM应用设计的评估指标来量化系统性能。这些指标并非基于传统的NLP评估方法,而是聚焦于LLM输出的独特特性,如答案与检索到的上下文的一致性(忠实度)、答案对提问的响应程度(答案相关性),以及检索到的上下文能否完全覆盖答案所需信息(上下文召回率)和是否包含冗余信息(上下文精确度)。通过这些客观指标,Ragas能够提供细致的性能分析,指导用户进行基于数据的功能改进和模型调优。
应用场景
RAG 系统开发与优化: 开发者在构建和迭代RAG系统时,可使用Ragas进行持续评估,确保检索和生成过程的质量,并发现性能瓶颈。
LLM 应用质量保证: 用于任何基于LLM的应用程序的性能测试和质量控制,确保其输出的准确性、相关性和可靠性。
模型选择与对比: 在选择不同RAG模型或LLM模型时,通过Ragas进行客观评估和对比,辅助决策。
研究与开发: 为LLM和RAG领域的研究人员提供标准化的评估工具,推动技术进步和性能基准的建立。
explodinggradients/ragas: Supercharge Your LLM Application Evaluations 🚀
3.RAG评估框架
简介
- Phoenix 是开源的 AI 可观测性平台,提供追踪、评估、数据集管理、实验、沙盒、提示管理等功能,支持多框架和大模型提供商,可在多环境运行。
- ChainForge 是开源的可视化大语言模型提示工程环境,能同时查询多个大模型,对比提示、模型和响应质量,支持设置评估指标和可视化结果。
核心功能
- Phoenix:支持追踪、评估、数据集创建、实验、沙盒优化、提示管理等,可对大语言模型应用进行实验、评估和故障排除。
- ChainForge:可快速测试提示想法和变体,对比响应质量,设置评估指标并可视化结果,利用 AI 简化流程。
技术原理
- Phoenix:基于 OpenTelemetry 实现运行时追踪,通过 OpenInference 项目实现自动检测,支持多种框架和大模型。
- ChainForge:基于 ReactFlow 和 Flask 构建,通过对输入提示模板的输入值进行交叉组合,实现对多个大模型的批量查询。
应用场景
Phoenix:适用于大语言模型应用的开发、评估和优化,可在本地、云端等环境使用。
ChainForge:用于大语言模型提示工程、模型选择和评估,可帮助开发者选择最佳提示和模型。
更多rag评估
4.多模态AI评估框架-谷歌
简介
LMEval是由Google发布的一个开源框架,旨在提供一个统一、高效且一致的评估工具,用于评估各种大型语言模型(LLMs)和多模态模型(如文本、图像和代码)。它致力于简化跨平台模型性能比较的复杂性,并为开发者和研究人员提供一个易于使用的标准化评估基准,以加速AI技术的普及和创新。
核心功能
- 跨模型与跨平台评估: 支持对不同提供商(如Gemini, GPT-4, Claude, Bedrock, Hugging Face, Vertex AI等)的LLM和多模态模型进行统一评估。
- 多模态支持: 能够评估文本、图像和代码等多种数据类型的模型,并支持轻松添加新的输入格式。
- 灵活的评估指标与基准: 提供标准化评估工具和基准测试,可用于评估模型性能、安全性和安全性(如Phare基准)。
- 用户友好与易用性: 提供示例Notebook,只需少量代码即可运行评估,降低了技术门槛。
- 可视化分析: 配备LMEvalboard,一个用于交互式模型比较和深度分析的仪表板工具。
- 规避响应识别: 具备识别模型规避性响应的能力,确保评估的全面性和准确性。
技术原理
- 统一接口层: LMEval利用LiteLLM框架,将不同LLM提供商(如OpenAI、Bedrock、Hugging Face、Vertex AI、Together AI、Azure、Groq等)的API调用格式统一转换为OpenAI API格式。LiteLLM负责翻译输入,以匹- 配各提供商针对补全、嵌入和图像处理的特定定要求,从而实现一次定义、多模型复用的评估基准。
- 多模态数据处理: 框架设计支持多种数据类型,通过内部抽象和数据管道处理机制,使其能够灵活地接入并评估文本、图像、代码等不同模态的数据。
- 可扩展的评估模块: LMEval采用模块化架构,允许用户自定义评估任务、指标和数据集,以适应特定的评估需求。其设计允许集成不同的评估器和模型,提升了框架的灵活性和扩展性。
应用场景
AI模型研发与优化: 研究人员和开发者可以利用LMEval快速比较不同大型语言模型和多模态模型的性能,指导模型选择、调优和迭代。
模型安全性与合规性评估: 结合Phare等独立基准测试,用于评估模型在安全、隐私和伦理方面的表现,确保模型符合相关标准。
跨平台模型基准测试: 对于需要同时部署和管理来自不同提供商的多个模型(如企业级应用),LMEval提供了一致的性能评估标准。
学术研究与论文发表: 为AI领域的学术研究提供了一个可复现、标准化的模型评估平台,便于研究成果的验证和比较。
AI应用开发与集成: 开发者在构建基于LLM和多模态模型的应用程序时,可以使用LMEval来测试和选择最适合其应用场景的模型,确保最终产品的性能和稳定性。
Announcing LMEval: An Open Source Framework for Cross-Model Evaluation | Google Open Source Blog
5.PII隐私保护
简介
Presidio 是微软开源的用于检测、编辑、屏蔽和匿名化敏感数据(PII)的框架,涵盖文本、图像和结构化数据。它提供快速识别和匿名化模块,能检测如信用卡号、姓名、位置等多种敏感信息,支持多语言,具有可扩展性和定制性。
核心功能
- 提供预定义或自定义的 PII 识别器,支持多种识别方式,如命名实体识别、正则表达式等。
- 可连接外部 PII 检测模型。
- 支持多种使用方式,包括 Python、PySpark、Docker 和 Kubernetes。
- 可定制 PII 识别和去识别过程。
- 具备图像 PII 文本编辑模块,支持标准图像和 DICOM 医学图像。
技术原理
Presidio 利用命名实体识别(NER)、正则表达式、基于规则的逻辑和校验和等技术,结合上下文信息,在多种语言中识别 PII 实体。同时,它支持连接外部 PII 检测模型,增强识别能力。对于图像,通过 OCR 技术识别文本,再进行 PII 处理。
应用场景
文本和图像中的敏感信息识别与去识别,保障数据隐私。
自动化和半自动化的 PII 去识别流程,适用于多平台。
处理结构化和半结构化数据中的敏感信息。
新LifeSim – 复旦与上海创智学院推出的长程用户生活模拟框架
周报归档:第 33 期 · 条目 1.2 · 2026-04-08 · 回看原周报 原始周报文件:
weekly_report_20260408_155302.md
LifeSim是复旦大学与上海创智学院联合研发的长程用户生活模拟框架,用于评测个性化AI助手的真实场景适配能力。它基于BDI认知模型融合用户内部认知与外部环境,生成连贯生活轨迹与多轮交互,并通过含1200个场景的LifeSim-Eval基准,精准测试模型处理显隐性意图、长期偏好建模的能力,填补现有评测与真实场景的鸿沟。
1.2.1 核心功能
- 长程生活轨迹模拟:依托3374条真实出行数据生成连贯事件序列,涵盖时间、地点、天气等环境约束,贴近真实生活节奏。
- 多轮交互行为模拟:模拟用户与AI助手的自然对话,支持记忆冲突检测、GoEmotions情绪推理和动态行为选择,还原真实交互逻辑。
- 个性化能力评测:通过LifeSim-Eval基准测试模型识别显隐性意图、长期偏好重建与对齐能力,覆盖8大生活领域的多维度评测。
- 隐私安全数据合成:生成百万级多样化用户画像,为个性化助手训练提供隐私安全的高质量合成数据,解决真实数据稀缺问题。
1.2.2 技术原理
LifeSim采用BDI(信念-愿望-意图)认知架构,由四大核心引擎协同工作:信念引擎整合长期用户画像(大五人格、偏好)与短期情境认知(物理/心理/环境状态);愿望引擎从11.3万条需求库检索候选意图,通过余弦相似度重排序后,用softmin函数采样生成用户意图;事件引擎基于逻辑函数控制事件触发概率,结合Foursquare真实出行轨迹与天气数据,确保事件符合时空约束;行为引擎通过记忆感知(语义相似度检测历史冲突)、情绪推理(GoEmotions分类)、行动选择三阶段,生成符合用户认知状态的自然对话。系统采用Qwen3-Embedding-0.6B作为检索模型,vLLM实现大模型高效部署,LLM-as-Judge完成7维度自动评分。
1.2.3 应用场景
- AI助手能力评测:为GPT-4o、Claude、DeepSeek等模型提供标准化长程个性化评测场景,精准定位隐性意图理解、长期记忆保持等能力边界。
- 合成数据生成:基于百万级模拟用户生成大规模长期交互对话数据,用于微调个性化助手或强化学习训练,规避真实数据隐私风险。
- 智能客服预训练:模拟用户连续多日焦虑等极端场景,测试客服系统的情感支持能力与长期上下文一致性,降低上线后真实用户测试风险。
- 人机交互研究:为认知科学、社会心理学提供可控实验平台,研究不同人格特质对AI助手接受度与信任建立的影响。
- 推荐算法验证:在饮食、健身等8大领域,验证推荐系统结合用户长期偏好与实时情境(如雨天+健身习惯)的动态调整能力。
- GitHub仓库:https://github.com/dfy37/lifesim
- arXiv技术论文:https://arxiv.org/pdf/2603.12152
- 在线体验Demo:http://fudan-disc.com/lifesim/
- 在线 Demo 体验:http://fudan-disc.com/lifesim/可使用可视化界面
Vision2Web – 清华联合智谱AI推出的视觉网站开发评估基准
周报归档:第 32 期 · 条目 1.10 · 2026-04-04 · 回看原周报 原始周报文件:
weekly_report_20260404_142629.md
Vision2Web是清华大学与智谱AI联合推出的多模态AI Agent视觉网站开发评估基准,包含193个真实网站任务,分静态网页生成、交互式前端开发、全栈网站构建三层递进难度。它采用工作流式Agent验证范式,通过GUI Agent验证功能正确性、VLM评判视觉还原度,能系统性揭示当前SOTA模型在复杂长程软件开发任务中的能力边界。
1.10.1 核心功能
- 三层递进式能力评估:从静态网页到全栈开发,逐级检验AI Agent的视觉理解与工程实现能力,精准定位不同阶段的能力短板。
- 双维度自动化验证:结合GUI Agent的功能正确性验证与VLM Judge的视觉还原度评估,实现客观可复现的端到端测试。
- 真实场景数据支撑:基于193个真实网站构建数据集,涵盖四大类16个子类,提供918张原型图与1255个测试用例,贴近实际开发需求。
- 系统性能力诊断:可精准定位Agent在跨模态推理、长程规划、复杂系统构建等环节的能力边界与失败原因。
1.10.2 技术原理
采用分层任务架构,将网站开发拆解为静态UI生成、交互式前端、全栈系统构建三个难度层级,实现能力解耦。基于C4验证集构建真实场景数据集,经结构评估、内容筛选、人工审核三阶段处理确保数据质量。创新性提出工作流式Agent验证范式,以有向依赖图建模测试流程,通过GUI Agent执行结构化功能测试节点,以VLM Judge完成组件级视觉一致性评分,解决传统测试在多模态、长程任务中可复现性差的问题。底层采用WebVoyager协议实现GUI Agent功能验证,通过GLM-4.6V与Gemini-3-Pro-preview分别实例化功能与视觉验证组件。
1.10.3 应用场景
- 模型能力评测:为Claude、Gemini、GPT等多模态大模型提供标准化的视觉网站开发能力基准测试,量化模型真实工程落地能力。
- Agent框架优化:对比OpenHands、Claude Code等不同Agent框架的性能表现,指导框架在长程规划、跨模态交互等模块的迭代升级。
- 算法研发验证:评估新模型在UI理解、代码生成、状态管理等关键技术上的创新效果,为算法迭代提供精准反馈。
- 产品能力对标:帮助AI建站产品量化自身水平,明确与SOTA模型的差距,指导产品功能优先级规划。
- 教育培训参考:作为教学案例库,用于培养AI辅助开发方向的工程师,提升开发者对多模态Agent开发的理解。
- arXiv技术论文:https://arxiv.org/pdf/2603.26648
harrier-oss-v1 – 微软开源的多语言文本嵌入模型
周报归档:第 32 期 · 条目 2.3 · 2026-04-04 · 回看原周报 原始周报文件:
weekly_report_20260404_142629.md
这是微软开源的多语言文本嵌入模型家族harrier-oss-v1,包含27B、0.6B、270M三个参数版本,在Multilingual MTEB v2基准测试中取得SOTA成绩。它能将文本转换为标准化高维向量,支持检索、聚类等多类任务,兼顾云端高性能与边缘低功耗需求,开源可商用。
2.3.1 核心功能
- 文本嵌入:将输入文本通过仅解码器架构转换为标准化高维密集向量,为下游任务提供语义基础。
- 语义检索:基于向量相似度实现高效文档搜索与信息召回,快速定位相关内容。
- 文本聚类:依据语义向量自动将相关文本分组归类,实现文本的智能整理。
- 相似度计算:量化评估两段文本的语义关联程度,可用于文本去重、内容推荐等场景。
- 跨语言任务支持:覆盖数十种语言,支持跨语言文本的语义对齐与匹配检索。
2.3.2 技术原理
模型采用仅解码器(Decoder-only)架构,通过对比学习目标在大规模多语言数据集上训练,270M和0.6B版本额外加入知识蒸馏优化。使用最后token池化策略,提取最后一个非padding token的嵌入作为句子表示,再经L2归一化生成标准化密集向量。支持通过自然语言指令定制不同场景的文本嵌入,需配合任务描述提示词使用。
2.3.3 应用场景
- 企业文档检索:适用于拥有多语言文档库的企业,员工输入查询指令,快速检索到语义相关的文档内容。
- 跨境电商内容管理:面向跨境电商平台,对多语言商品描述、用户评论进行聚类分析,实现内容的分类整理。
- 跨语言内容推荐:为国际化内容平台提供支持,根据用户输入的文本,推荐不同语言的语义相似内容。
- 学术文献整理:针对科研人员,对多语言学术文献进行语义分类和相似度计算,辅助文献综述工作。
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-0.6b
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-270m
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-27b
新Vision2Web – 清华联合智谱AI推出的视觉网站开发评估基准
周报归档:第 31 期 · 条目 1.3 · 2026-04-01 · 回看原周报 原始周报文件:
weekly_report_20260401_164414.md
Vision2Web是清华大学与智谱AI联合推出的视觉网站开发评估基准,用于评测多模态AI Agent的端到端建站能力。它包含193个真实网站任务,分为静态网页生成、交互式前端开发、全栈网站构建三层递进难度,通过工作流式Agent验证范式,能系统性揭示当前模型在复杂长程软件开发中的能力边界。
1.3.1 核心功能
- 三层递进式能力评估:从静态网页到全栈开发逐级测试,精准检验AI Agent的视觉理解与工程实现能力梯度。
- 双维度自动化验证:由GUI Agent验证功能正确性,VLM Judge评估视觉还原度,实现客观可复现的端到端测试。
- 真实场景数据支撑:基于193个真实网站构建数据集,涵盖四大类16个子类,提供918张原型图与1255个测试用例。
- 系统性能力诊断:精准定位Agent在跨模态推理、长程规划、复杂系统构建等环节的能力短板与失败原因。
1.3.2 技术原理
采用分层任务架构,将评估拆解为静态网页、交互式前端、全栈网站三个难度层级,构建依赖于C4验证集真实网站的多模态数据集,经结构评估、内容筛选、人工审核三步提纯。核心采用工作流式Agent验证范式,将测试转化为有向依赖图,GUI Agent基于WebVoyager协议执行专家设计的测试工作流,通过状态跟踪与动作约束验证功能正确性;VLM Judge基于结构化提示进行组件级视觉对比,按预设规则输出视觉相似度得分,最终综合功能与视觉得分完成评估。
1.3.3 应用场景
- 模型能力评测:为Claude、Gemini、GPT等多模态大模型提供标准化的视觉网站开发能力基准测试,量化模型建站水平。
- Agent框架优化:对比OpenHands、Claude Code等不同框架的性能表现,定位框架在任务规划、跨页协调等环节的不足,指导迭代升级。
- 算法研发验证:用于评估新模型在UI理解、代码生成、长程规划等关键技术上的创新效果,为算法优化提供数据支撑。
- 产品能力对标:帮助AI建站产品量化自身开发能力,明确与SOTA模型的差距,制定产品迭代方向。
- 教育培训参考:作为AI辅助开发教学案例库,用于培养工程师对多模态Agent建站流程与能力边界的认知。
- arXiv技术论文:https://arxiv.org/pdf/2603.26648
新harrier-oss-v1 – 微软开源的多语言文本嵌入模型
周报归档:第 31 期 · 条目 2.2 · 2026-04-01 · 回看原周报 原始周报文件:
weekly_report_20260401_164414.md
harrier-oss-v1是微软开源的多语言文本嵌入模型系列,包含27B、0.6B、270M三种参数规模版本,在Multilingual MTEB v2基准测试中取得SOTA成绩。它能将文本转换为高维密集向量,支持检索、聚类、语义相似度计算等多类任务,兼顾云端高性能与边缘低功耗部署需求。
2.2.1 核心功能
- 文本嵌入:将多语言文本编码为标准化高维密集向量,保留语义特征。
- 语义检索:基于向量相似度快速召回相关文档,实现精准信息查找。
- 文本聚类:依据语义向量自动将文本分组,完成主题归类与数据整理。
- 相似度计算:量化评估两段文本的语义关联程度,支持文本去重等场景。
- 跨语言匹配:实现不同语言文本的语义对齐,支持跨语种检索与双语挖掘。
2.2.2 技术原理
该模型采用仅解码器架构,通过对比学习在多语言数据集上预训练,小参数版本额外加入知识蒸馏提升性能。使用最后token池化策略,提取文本序列最后一个非padding token的嵌入向量,再经L2归一化得到标准语义向量。查询需配合任务指令输入,通过自然语言定制嵌入效果,文档端无需额外指令。
2.2.3 应用场景
- 企业知识库检索:企业员工可基于语义向量快速查找内部文档、政策资料,提升信息获取效率。
- 多语种内容聚类:媒体平台可对多语言新闻、社交内容自动聚类,快速梳理热点主题。
- 跨语种内容推荐:跨境电商基于用户浏览文本的语义向量,为不同语种用户推送匹配商品。
- 文本数据去重:内容审核平台通过计算文本相似度,批量清理重复的多语言垃圾信息。
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-0.6b
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-270m
- HuggingFace模型库:https://huggingface.co/microsoft/harrier-oss-v1-27b