LLM合集-多模态
LLM合集-多模态模块构建了涵盖30+个前沿多模态大模型的完整技术生态,专注于视觉-语言、音频-语言等跨模态AI技术的创新应用。该模块系统性地整理了OpenAI GPT-4V、Google Gemini Vision、Anthropic Claude 3、Meta LLaVA系列等国际领先的视觉语言模型,以及阿里通义千问VL、百度文心一言4.0、腾讯混元多模态、字节豆包视觉版、智谱GLM-4V、月之暗面Kimi视觉等国产优秀多模态模型。技术特色涵盖了图像理解、视频分析、音频处理、3D感知等多维度感知能力,详细解析了Vision Transformer、CLIP、DALL-E、Stable Diffusion等核心技术架构,以及视觉编码器、跨模态注意力、多模态融合等关键技术机制。
模块深入介绍了图像描述生成、视觉问答、图文检索、视频理解、音频转录、语音合成等典型应用场景,以及多模态数据预处理、模型训练策略、推理优化、部署方案等工程化实践。内容还包括多模态评测基准(VQA、COCO Caption、BLIP)、开源项目生态(LLaVA、MiniGPT-4、InstructBLIP)、商业API服务、性能对比分析等实用资源,以及最新技术突破、应用创新、发展趋势等前沿洞察,帮助开发者构建具备丰富感知能力的下一代AI应用,实现文本、图像、音频、视频等多模态信息的智能理解和生成。
多模态
目录
- 1.Nexus-Gen魔塔文生图
- 1.Seed1.5-VL字节
- 2.Matrix-Game空间大模型-昆仑万维
- 2.Step1X-3D 阶跃星辰 3D生成模型
- 2.bytedance ContentV文生视频
- 2.字节BAGEL多模态模型
- 2.谷歌系列
- 2.谷歌系列/Graphiti-AI动态知识图谱
- 2.通义万相-开源视频模型
- 3.MoviiGen 1.1
- 3.meta-vjepa世界模型
- 4.3D生成模型Partcrafter
- 4.MAGREF多主体视频生成框架-字节
- 4.OmniAudio空间音频生成
- 4.PlayDiffusion音频编辑
- 4.SeedVR2-字节视频修复
- 4.美团-肖像生成llia
- 5.多人对话视频框架
- 5.趣丸科技-人脸动画生成
- Kwai Keye VL 快手
- OmniAvatar浙大阿里视频生成
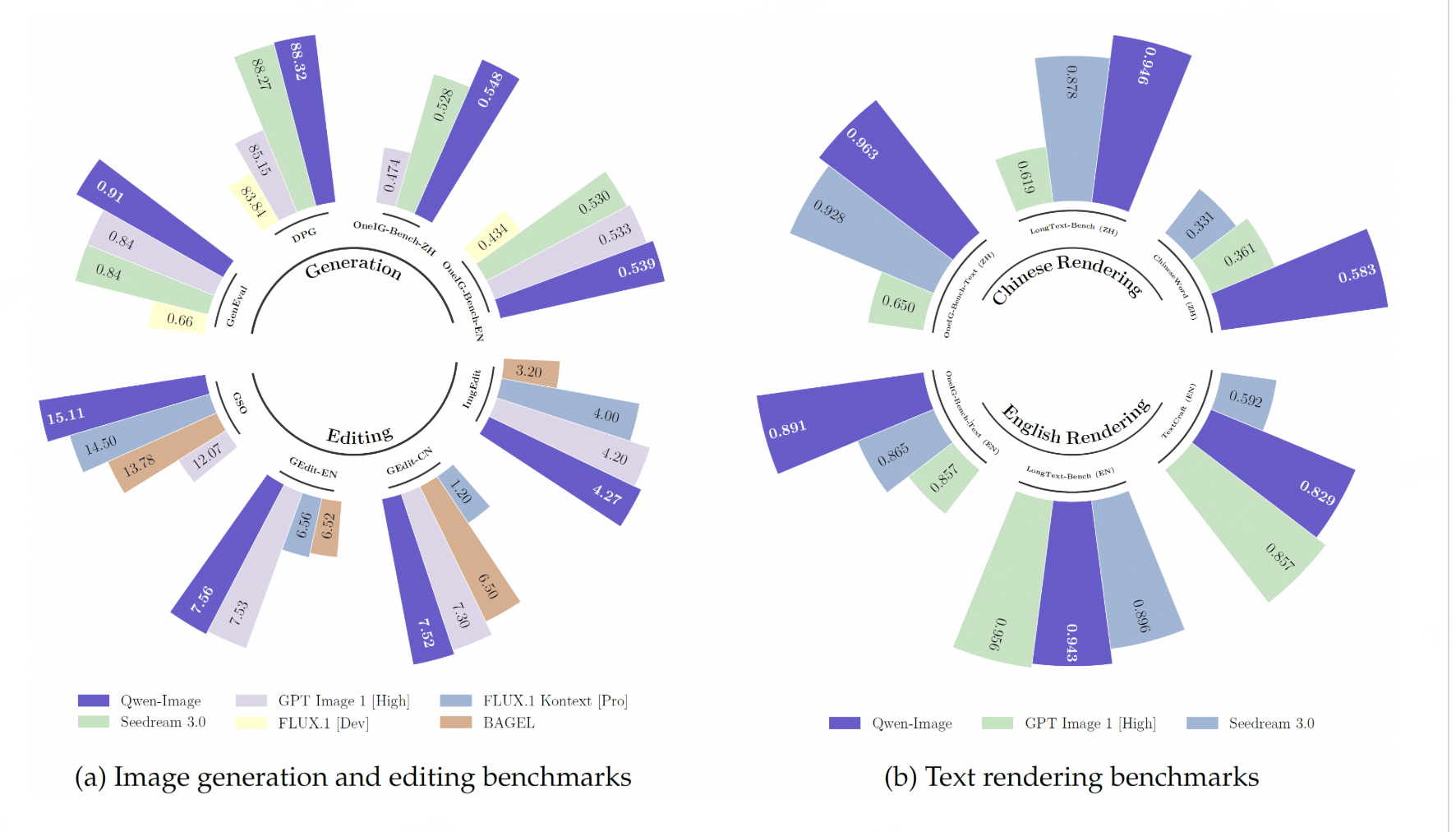
Qwen-Image – 阿里通义千问开源的文生图模型
简介
通义千问视觉基础模型(Qwen-Image)是由阿里云QwenLM团队开发的一款20亿参数的MMDiT(Multi-Modal Diffusion Transformer)图像基础模型。该模型在复杂的文本渲染和精准的图像编辑方面取得了显著进展,旨在提供高质量的图文生成与编辑能力。

核心功能
- 高保真文本渲染: 能够在生成的图像中实现高精度的文本呈现,无论是英文字母还是中文字符,都能保持排版细节、布局一致性和上下文和谐性,实现文本与图像的无缝融合。
- 精准图像编辑: 提供强大的图像编辑能力,包括但不限于图像生成、内容估计、新视角合成和超分辨率等。
- 复杂场景生成: 支持根据复杂的文本描述生成视觉上连贯且高质量的图像。
- 跨语言文本支持: 能够处理并生成包含多种语言文本的图像。
技术原理
Qwen-Image是一个基于MMDiT架构的20亿参数基础模型。MMDiT(Multi-Modal Diffusion Transformer)结合了扩散模型(Diffusion Model)的图像生成能力和Transformer架构处理序列数据的优势。其核心原理可能涉及:
- 多模态融合: 有效地将文本提示信息与视觉特征相结合,指导图像生成和编辑过程。
- 扩散模型: 逐步去噪生成图像,从而实现高保真和细节丰富的输出。
- Transformer结构: 用于捕捉长距离依赖关系和处理复杂的语义信息,尤其在文本理解和图像内容布局方面发挥关键作用。
- 参数量与训练: 20亿参数表明模型规模庞大,通过大规模数据集训练,赋予其强大的泛化能力和对图像复杂性的理解。
应用场景
- 创意内容生成: 广泛应用于广告、设计、媒体等领域,用于快速生成包含定制文本和视觉效果的图片。
- 智能图像编辑: 辅助专业设计师或普通用户进行图像的精细化修改、内容添加或修复。
- 多语言本地化: 帮助企业和创作者生成带有不同语言文本的图像,以适应全球市场需求。
- 自动化设计工具: 集成到自动化设计平台中,实现文本到图像的智能转换,提高工作效率。
- 虚拟现实与游戏: 用于快速生成场景、道具或角色纹理,包含特定文字元素。
Qwen-Image的项目地址
- GitHub仓库:https://github.com/QwenLM/Qwen-Image
- HuggingFace模型库:https://huggingface.co/Qwen/Qwen-Image
- 技术论文:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf
- 在线体验Demo:https://huggingface.co/spaces/Qwen/Qwen-Image
1.Nexus-Gen魔塔文生图
简介
Nexus - Gen是一个统一模型,将大语言模型(LLM)的语言推理能力与扩散模型的图像合成能力相结合,通过双阶段对齐训练过程,使模型具备处理图像理解、生成和编辑任务的综合能力。2025年5月27日使用BLIP - 3o - 60k数据集微调后,提升了图像生成对文本提示的鲁棒性。
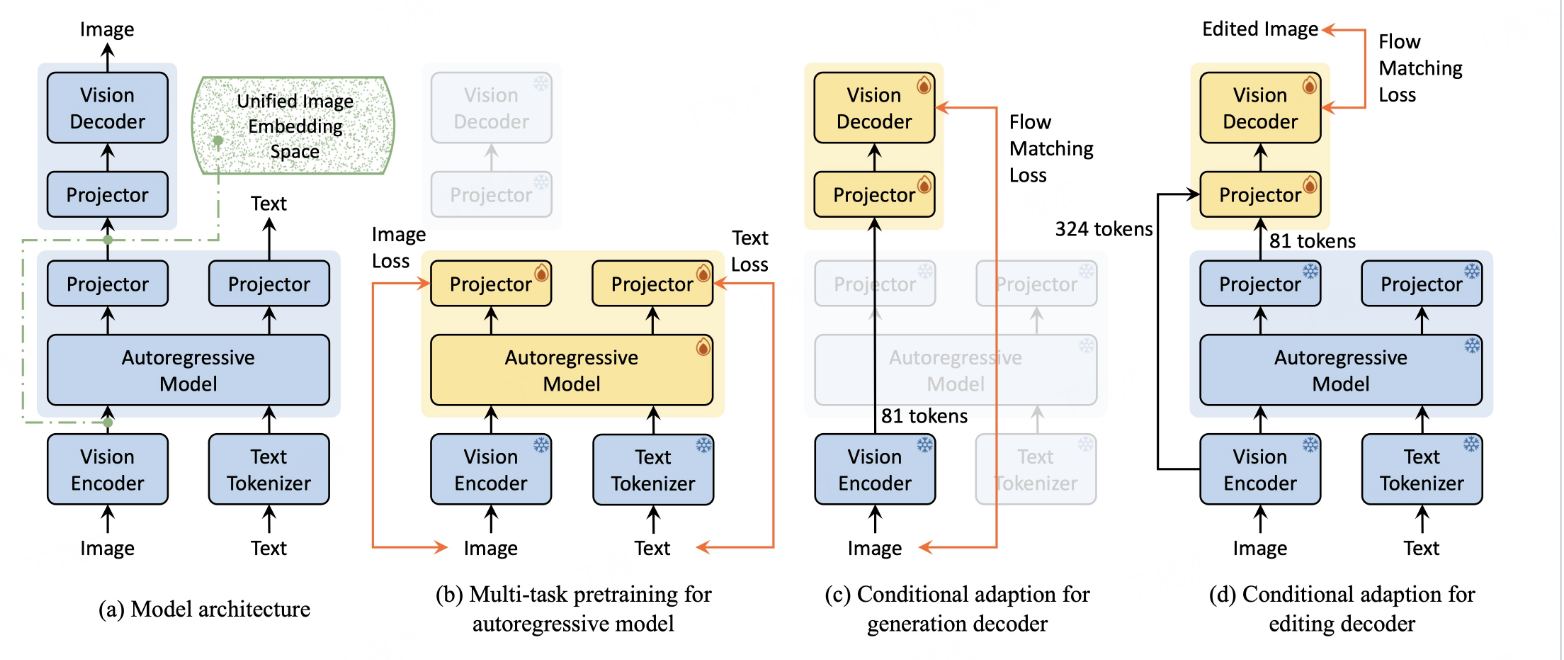
核心功能
- 图像理解:能对图像进行理解分析。
- 图像生成:依据文本提示生成高保真图像,可使用预填充自回归策略提升生成质量,还支持使用较少显存生成图像。
- 图像编辑:对已有图像进行编辑处理。
技术原理
通过双阶段对齐训练过程,使大语言模型和扩散模型的嵌入空间对齐。一是自回归大语言模型学习基于多模态输入预测图像嵌入;二是视觉解码器训练从这些嵌入中重建高保真图像。训练大语言模型时,引入预填充自回归策略避免连续嵌入空间中误差积累导致的生成质量下降问题。
应用场景
图像创作:根据文字描述生成艺术作品、设计素材等。
图像编辑:对照片、设计图等进行修改完善。
图像分析:辅助理解图像内容,如智能图像标注等。
1.Seed1.5-VL字节
简介
Seed1.5-VL 是由字节跳动发布的一款视觉 - 语言基础模型,专注于提升多模态理解与推理能力。它采用 5.32 亿参数的视觉编码器和 200 亿激活参数的混合专家(MoE)大语言模型,在 60 项公开评测基准中的 38 项取得 SOTA 表现。
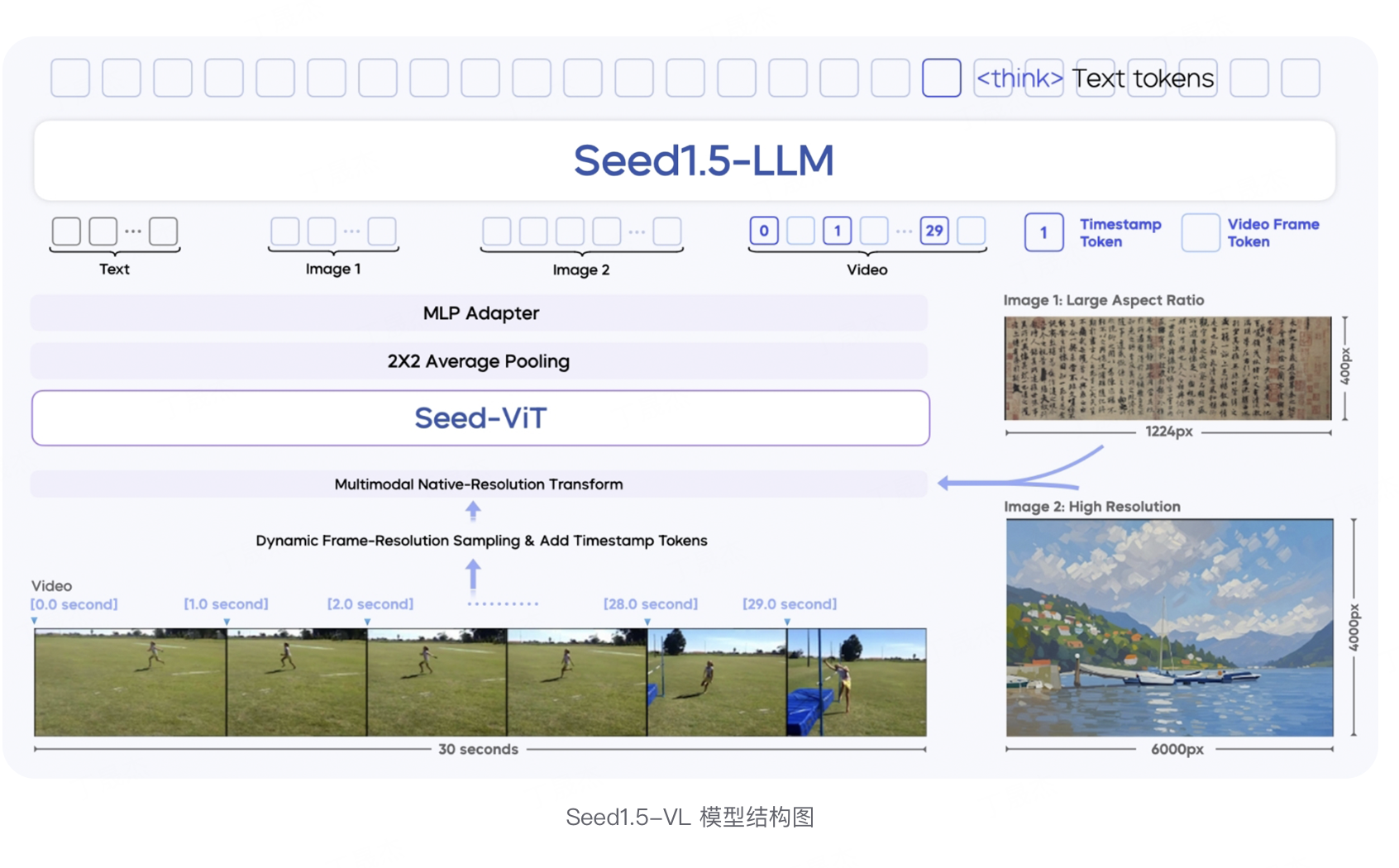
核心功能
- 多模态理解:支持图像、视频等多模态输入,能处理复杂推理、OCR、图表理解、视觉定位等任务。
- 智能体交互:在 GUI 控制、游戏玩法等交互式智能体任务中表现出色。
- 格式转换:可将 txt 文件转换为 epub 格式。
技术原理
- 模型架构:由 SeedViT 编码图像和视频、MLP 适配器投射视觉特征、大语言模型处理多模态输入并推理。
- 图像与视频处理:支持多分辨率图像输入,用原生分辨率变换保留细节;视频处理采用动态帧分辨率采样策略,引入时间戳标记增强时间信息感知。
- 预训练:使用 3 万亿源标记的预训练语料库,多数子类数据训练损失与训练标记数遵循幂律关系。
- 后训练:结合拒绝采样和在线强化学习迭代更新,监督信号仅作用于最终输出结果。
应用场景
内容识别:识别图片中的地点、物体等。
视觉谜题解答:根据表情符号等视觉元素联想电影等。
文件格式转换:将 txt 文件转换为 epub 格式。
智能体操作:进行 GUI 智能体任务,如设置软件全局热键等。
2.谷歌系列
简介
Imagen图像生成模型,它是目前最佳的图像生成模型,可生成具有逼真细节、清晰画质、改进拼写和排版的图像,涵盖风景、人物、动物、漫画、包装等多种场景,能将用户的想象快速转化为生动的视觉呈现。谷歌DeepMind推出的视频生成模型Veo,包括最新的Veo 3及Veo 2的新创意功能。Veo 3具有更高的真实感、更好的指令遵循能力,能原生生成音频;Veo 2在控制、一致性和创造性方面有新提升,还具备参考图像生成视频、匹配风格等功能。该模型在视频生成领域表现出色,但在自然连贯的语音音频方面仍在发展。此外,还介绍了其在影视、游戏等行业的应用案例。
核心功能
- 图像生成:依据用户输入的文本描述,生成具有高度真实感的图像,包括不同场景、生物、物品等。
- 细节捕捉:能够捕捉极端特写,呈现丰富的颜色、纹理和渐变,使图像具有可触摸感。
- 拼写排版优化:在漫画、包装和收藏品等方面,实现改进的拼写、更长的文本字符串以及新的布局和样式。
- 视频生成:根据文本描述生成具有高真实感和细节的视频,涵盖多种场景和风格。
- 音频生成:Veo 3可原生生成音效、环境噪音和对话等音频。
- 视频编辑:包括相机控制、添加或移除物体、角色控制、运动控制、外绘画、首末帧过渡等功能。
应用场景
艺术创作:帮助艺术家、设计师快速将创意转化为图像,用于绘画、插画、漫画等创作。
商业设计:如产品包装设计、广告宣传海报、品牌形象设计等。
娱乐行业:为游戏、影视制作生成场景、角色、道具等概念图。
影视制作:从脚本到故事板制作,提升电影制作流程效率。
游戏开发:为游戏提供视觉体验,如在地下城爬行游戏中充当主持人、引导者和互动角色。
创意工具开发:开发者可将Veo与其他生成媒体技术结合,创造新型创意工具。
Graphiti-AI动态知识图谱
简介
Graphiti是一个用于构建和查询时态感知知识图谱的框架,专为动态环境中的AI智能体设计。它能将用户交互、企业数据和外部信息整合到可查询的图谱中,支持增量数据更新、高效检索和精确历史查询,适用于开发交互式、上下文感知的AI应用。
核心功能
- 数据整合:集成和维护动态用户交互与业务数据。
- 推理与自动化:促进智能体基于状态的推理和任务自动化。
- 数据查询:支持语义、关键字和基于图的搜索方法,查询复杂且不断演变的数据。
- 管理操作:具备事件管理、实体管理、关系处理、语义和混合搜索、组管理、图维护等功能。
技术原理
- 双时态数据模型:显式跟踪事件发生和摄取时间,实现精确的时间点查询。
- 高效混合检索:结合语义嵌入、关键字(BM25)和图遍历,实现低延迟查询。
- 自定义实体定义:通过Pydantic模型灵活创建本体并支持开发者定义实体。
- 可扩展性:利用并行处理高效管理大型数据集。
应用场景
销售与客服:支持智能客服学习用户交互,融合个人知识与业务系统动态数据。
医疗健康:辅助医疗智能体执行复杂任务,基于多源动态数据进行推理。
金融领域:助力金融智能应用进行长期记忆和基于状态的推理。
getzep/graphiti: Build Real-Time Knowledge Graphs for AI Agents
2.通义万相-开源视频模型
简介
该链接指向ModelScope主页,提供模型、数据集、工作室等资源。包含快速入门指引,有本周热门模型、数据集和工作室展示。平台提供Studio用于构建和展示AI应用,还有开源框架辅助模型开发和应用构建,以及评估、训练推理等工具。
核心功能
- 模型与数据集展示:展示行业最新模型和数据集。
- 应用展示空间:Studio提供免费灵活的AI应用展示与构建空间。
- 框架工具支持:有Eval - Scope用于大模型评估,Swift用于大模型训练推理,ModelScope - Agent连接模型与外界。
技术原理
- 统一框架:ModelScope Library作为统一网关,实现高效模型推理、微调与评估。
- 模型托管:ModelHub作为开源中心,托管AI模型和数据集。
- 评估定制:Eval - Scope通过可定制框架进行大模型性能基准测试。
- 多模型支持:Swift支持多种模型和训练方式。
应用场景
模型开发:开发者基于平台模型和工具开发新AI模型。
应用构建:利用Studio构建和展示不同AI应用。
模型评估:使用Eval - Scope评估大模型性能。
模型比较:通过CompassArena体验和比较多款主流大模型效果。
2.字节BAGEL多模态模型
简介
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数(70亿活跃参数)。采用混合变换器专家架构(MoT),通过双编码器分别捕捉图像像素级和语义级特征,经海量多模态标记数据预训练。在多模态理解基准测试中超越部分顶级开源视觉语言模型,具备图像与文本融合理解、视频内容理解、文本到图像生成等多种功能。

核心功能
- 多模态交互:处理图像和文本的混合输入输出,支持对话交流。
- 内容生成:生成高质量图像、视频帧或图文交织内容。
- 图像编辑:进行自由形式的图像编辑,保留视觉细节。
- 风格迁移:转换图像风格。
- 导航功能:在不同环境中进行路径规划和导航。
- 多模态推理:融合多模态数据进行推理,完成复杂任务。
技术原理
- 架构设计:采用混合变换器专家架构(MoT),含两个独立编码器,分别处理图像像素级和语义级特征。
- 专家混合机制:编码器内有多个专家模块,动态选择合适专家组合处理多模态数据。
- 标记化处理:将多模态数据转化为标记,图像分割成小块,文本按单词或子词处理。
- 训练范式:遵循"下一个标记组预测"范式,用海量多模态标记数据预训练。
应用场景
- 内容创作:生成图像、视频,进行创意广告制作。
- 教育领域:可视化复杂概念,辅助学习。
- 电商平台:生成产品3D模型和虚拟展示,提升购物体验。
- 智能交互:支持图像和文本混合的对话交流。
- BAGEL - 字节跳动开源的多模态基础模型 | AI工具集
- ByteDance-Seed/BAGEL-7B-MoT · Hugging Face
- ByteDance-Seed/Bagel
- BAGEL: The Open-Source Unified Multimodal Model
2.bytedance ContentV文生视频
简介
ContentV 是字节跳动推出的一个高效视频生成模型框架,其 8B 开源模型基于 Stable Diffusion 3.5 Large 和 Wan - VAE,在 256×64GB NPUs 上仅训练 4 周就在 VBench 测试中取得 85.14 的成绩。它通过创新架构、训练策略和反馈框架,能根据文本提示生成多分辨率、多时长的高质量视频。
核心功能
- 文本到视频生成:依据文本提示生成多样化、高质量视频。
- 保证视频质量:确保生成视频具有高时间一致性和视觉质量。
- 内容多样:可生成涵盖人类、动物、场景等多类别的视频。
技术原理
- 架构设计:采用简约架构,最大程度复用预训练图像生成模型进行视频合成。
- 训练策略:运用基于流匹配的系统多阶段训练策略,提升训练效率。
- 反馈框架:采用具成本效益的基于人类反馈的强化学习框架,在无需额外人工标注的情况下提高生成质量。
应用场景
影视制作:为影视创作提供视频素材和创意灵感。
广告宣传:快速生成各类产品宣传视频。
教育领域:制作教学视频,丰富教学内容。
ContentV: Efficient Training of Video Generation Models with Limited Compute
2.Matrix-Game空间大模型-昆仑万维
简介
Matrix - Game是一个拥有170亿参数的交互式世界基础模型,用于可控的游戏世界生成。它采用两阶段训练流程,先进行无标签预训练理解环境,再进行有动作标签的微调以实现交互式视频生成。配套有含细粒度动作注释的大规模Minecraft数据集Matrix - Game - MC。通过GameWorld Score基准评估,在多个指标上优于先前的开源Minecraft世界模型。
核心功能
- 交互式生成:基于扩散的图像到世界模型,根据键盘和鼠标输入生成高质量视频,实现细粒度控制和动态场景演变。
- 游戏世界评估:GameWorld Score基准,从视觉质量、时间质量、动作可控性和物理规则理解四个关键维度评估Minecraft世界模型。
- 支持大规模训练:Matrix - Game数据集支持交互式和基于物理的世界建模的可扩展训练。
- 精准控制:能精确控制角色动作和相机移动,保持高视觉质量和时间连贯性。
技术原理
Matrix - Game采用图像到世界的生成范式,以单张参考图像作为世界理解和视频生成的主要先验。使用自回归策略保持片段间的局部时间一致性,实现长时间视频生成。模型训练分两阶段,先无标签预训练理解环境,后有动作标签微调实现交互式视频生成。
应用场景
- 游戏开发:用于生成多样化Minecraft场景及其他虚幻引擎构建的游戏场景的高质量交互式视频。
- 游戏测试:通过评估模型的可控性和物理合理性,辅助测试游戏的操作体验和物理规则表现。
- SkyworkAI/Matrix-Game: Matrix-Game: Interactive World Foundation Model
- Matrix-Game: Interactive World Foundation Model
2.Step1X-3D 阶跃星辰 3D生成模型
简介
Step1X-3D 是一个专注于高质量、可控生成带纹理三维资产的开源框架。它旨在解决当前三维生成领域数据稀缺、算法局限性以及生态系统碎片化等挑战,通过先进的技术实现高保真几何和多样化纹理贴图的生成,并确保几何与纹理之间的高度对齐。
核心功能
- 高保真3D资产生成: 能够从单张图像生成具有高精细几何和多样纹理贴图的3D模型。
- 可控的几何与纹理: 支持对生成的3D模型进行控制,例如调整对称性、边缘类型(尖锐、普通、平滑)以及纹理风格(卡通、素描、照片级真实感)。
- 纹理与几何对齐: 确保生成的纹理与模型几何形状精确匹配,避免错位或不协调。
- 开放框架: 提供完整的模型、训练代码和适配模块,促进3D生成领域的开放研究和复现性。
技术原理
Step1X-3D 采用两阶段3D原生架构:
- 几何生成阶段: 使用混合3D VAE-DiT(变分自编码器-扩散Transformer)扩散模型生成截断有符号距离函数 (TSDF),随后通过行进立方体算法将其网格化,以构建高质量的3D几何。
- 纹理合成阶段: 利用经过微调的 SD-XL(Stable Diffusion XL)多视图生成器。该生成器以生成的几何和输入图像为条件,产生视图一致的纹理,并烘焙到3D模型上。
- 此外,该框架还包括一个严格的数据整理管道,处理并筛选出高质量的3D资产数据集,以支持模型训练。
应用场景
游戏开发: 快速生成游戏角色、道具和环境的3D模型,提高开发效率。
虚拟现实 (VR) / 增强现实 (AR): 创建沉浸式VR/AR体验所需的丰富3D内容。
数字艺术与设计: 为艺术家和设计师提供强大的工具,快速实现3D创意构想。
元宇宙构建: 自动化生成元宇宙中的各类数字资产。
工业设计与原型: 辅助产品设计与原型制作,实现快速迭代。
3.MoviiGen 1.1
简介
MoviiGen 1.1 是基于 Wan2.1 的尖端视频生成模型,在电影美学和视觉质量上表现出色。经专业人士评估,它在氛围营造、镜头运动和物体细节保留等关键电影维度表现卓越,能生成清晰度和真实感高的视频,适用于专业视频制作和创意应用。
核心功能
- 高质量视频生成:生成具有出色清晰度和细节的 720P、1080P 视频,保持视觉质量一致。
- 专业电影美学呈现:在氛围营造、镜头运动和物体细节保留方面表现优异。
- 支持提示扩展推理:可使用提示扩展模型优化生成效果。
技术原理
- 训练框架:基于 FastVideo,采用序列并行优化内存使用和训练效率,通过自定义实现将时间维度分配到多个 GPU,减少单设备内存需求。
- 数据处理:将视频和文本提示缓存为潜在变量和文本嵌入,减少训练阶段计算开销。
- 混合精度训练:支持 BF16/FP16 训练加速计算。
应用场景
专业影视制作:用于创作具有电影质感的视频内容。
创意设计领域:辅助设计师实现高保真的视觉创意。
虚拟现实和游戏:生成高质量的场景和角色动画。
ZulutionAI/MoviiGen1.1: MoviiGen 1.1: Towards Cinematic-Quality Video Generative Models
4.3D生成模型Partcrafter
简介
PartCrafter是首个结构化3D生成模型,可从单张RGB图像联合合成多个语义有意义且几何不同的3D网格。它基于预训练的3D网格扩散变压器,引入组合潜在空间和分层注意力机制,无需预分割输入,能同时对多个3D部分去噪,实现端到端的部件感知生成。研究还整理了新数据集支持部件级监督,实验表明其在生成可分解3D网格方面优于现有方法。
核心功能
- 多部件3D网格生成:从单张RGB图像一次性联合生成多个语义和几何不同的3D网格,可用于生成单个物体或复杂多物体场景。
- 端到端部件感知生成:无需图像分割输入,同时对多个3D部分去噪,实现端到端的部件感知生成。
- 支持不可见部件生成:能够自动推断输入图像中不可见的3D结构。
技术原理
- 基于预训练模型:构建于在完整物体上训练的预训练3D网格扩散变压器(DiT),继承预训练权重、编码器和解码器。
- 组合潜在空间:每个3D部分由一组解纠缠的潜在令牌表示,添加可学习的部件身份嵌入区分不同部件。
- 分层注意力机制:包括局部注意力和全局注意力,局部注意力捕获每个部件内的局部特征,全局注意力实现所有部件间的信息流动,确保生成过程中的全局一致性和部件级细节。
- 训练目标:通过整流流匹配训练,将噪声高斯分布映射到数据分布。
应用场景
3D建模与设计:辅助设计师快速从2D图像生成具有多个部件的3D模型,提高设计效率。
游戏与动画制作:用于生成游戏和动画中的3D场景和物体,丰富场景内容和物体细节。
机器人训练:提供准确和部件感知的3D表示,帮助机器人更好地理解和与环境交互。
虚拟和增强现实:为VR/AR应用生成高质量的3D场景和物体,提升用户体验。
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
4.OmniAudio空间音频生成
简介
OmniAudio是一个用于从360度视频生成一阶Ambisonics(FOA)空间音频的框架。论文作者提出了360V2SA新任务,构建了大规模数据集Sphere360,采用自监督预训练和双分支架构,在客观和主观指标上均达到了最先进的性能。项目网站提供相关信息,GitHub仓库提供代码。
核心功能
- 空间音频生成:从360度视频中生成FOA格式的空间音频,准确捕捉声音的方向和空间信息。
- 数据处理:构建并清理Sphere360数据集,包含103,000个真实世界的视频片段,涵盖288种音频事件。
- 模型训练:采用自监督的粗到细预训练策略,结合非空间和空间音频数据进行预训练,然后进行视频引导的微调。
技术原理
- 条件流匹配:使用时间相关的速度向量场,通过最小化目标函数来训练模型,生成从噪声到数据的概率路径。
- 变分自编码器(VAE):对FOA音频进行编码和解码,通过修改Stable Audio框架,适应四通道FOA音频。
- 双分支视频表示:利用冻结的预训练MetaCLIP - Huge图像编码器,分别处理全景视频和透视视频,融合两种表示以捕捉局部和全局信息。
应用场景
虚拟现实和增强现实:为VR/AR体验提供更真实的音频环境,增强沉浸感。
内容创作:帮助创作者轻松为视频添加音效、背景音乐或旁白。
教育和培训:为教育视频自动生成音频解释,使学习体验更具吸引力。
历史保护:为无声的历史镜头添加生成的音频,重现历史场景。
4.PlayDiffusion音频编辑
简介
PlayDiffusion是Play.AI推出的一款基于扩散模型的音频编辑模型,已开源。它解决了传统自回归模型在音频编辑时的局限性,能实现高质量、连贯的音频编辑,还可作为高效的文本转语音系统。
核心功能
- 音频编辑:对音频特定部分进行修改、替换,且能保持音频连贯性和自然度。
- 文本转语音:在全音频波形被掩码的极端情况下,可作为高效的TTS系统。
技术原理
- 编码与掩码:将音频序列编码为离散空间的令牌,修改时掩码相应部分。
- 扩散模型去噪:以更新后的文本为条件,用扩散模型对掩码区域去噪。
- 解码转换:通过BigVGAN解码器将输出令牌序列转换为语音波形。
- 训练优化:采用非因果掩码、自定义分词器和嵌入缩减、说话人条件等技术训练模型。
应用场景
音频内容创作:对已有音频进行精细修改和调整。
有声读物制作:将文本高效转换为语音。
语音交互系统:优化语音合成的质量和效率。
5.多人对话视频框架
简介
MultiTalk是用于音频驱动的多人对话视频生成的开源框架。输入多流音频、参考图像和提示词,可生成包含符合提示的互动且嘴唇动作与音频一致的视频。它支持单人和多人视频生成、交互式角色控制、卡通角色和唱歌视频生成,具有分辨率灵活、可生成长达15秒视频等特点。
核心功能
- 生成对话视频:支持单人和多人对话视频生成,实现嘴唇动作与音频同步。
- 角色交互控制:通过提示词直接控制虚拟人物动作。
- 泛化性能佳:支持卡通角色和唱歌视频生成。
- 灵活分辨率:可输出480p和720p任意宽高比视频。
- 长视频生成:支持长达15秒视频生成。
- 指令跟随:支持通过提示词直接控制虚拟人物动作。
技术原理
- 基础架构:采用基于DiT的视频扩散模型,结合3D变分自编码器(VAE),利用文本编码器生成文本条件输入,通过解耦交叉注意力将CLIP图像编码器提取的全局上下文注入DiT模型。
- 音频嵌入提取:使用Wav2Vec提取声学音频嵌入,并将当前帧附近的音频嵌入拼接。
- 音频适配压缩:在音频交叉注意力层,通过音频适配器对音频进行压缩,使视频潜在帧长度与音频嵌入匹配。
- 多流音频注入:提出四种注入方案,引入自适应人物定位方法和L - RoPE方法解决音频与人物绑定问题。
- 训练策略:采用两阶段训练、部分参数训练和多任务训练,保留基础模型的指令跟随能力。
- 长视频生成:采用基于自回归的方法,将先前生成视频的最后5帧作为额外条件进行推理。
应用场景
- 影视制作:用于制作多角色电影场景。
- 电商直播:生成主播与观众互动的视频。
- 动画创作:创作卡通角色对话、唱歌的动画视频。
- MeiGen-AI/MultiTalk: Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
- MeiGen-AI/MeiGen-MultiTalk · Hugging Face
- arxiv.org/pdf/2505.22647
- multi-talk官网
5.趣丸科技-人脸动画生成
简介
Playmate 是一个通过3D隐式空间引导扩散模型实现人像动画灵活控制的框架。它旨在解决现有口型同步、头部姿态不准确以及缺乏精细表情控制等挑战,从而生成高质量、可控的逼真说话人脸视频。
核心功能
- 逼真说话人脸生成: 能够根据音频输入生成高度逼真的说话人脸视频。
- 精准唇形同步: 显著提高视频中人物唇部动作与语音的同步准确性。
- 灵活头部姿态控制: 允许用户对生成视频中的头部姿态进行精确调整和控制。
- 精细情感表达控制: 通过情感控制模块,实现对生成视频中人物情感的细粒度控制。
- 两阶段训练框架: 采用分阶段训练方法,优化属性解耦和运动序列生成。
技术原理
Playmate 采用一个两阶段训练框架,核心是3D隐式空间引导扩散模型。
- 第一阶段: 利用**运动解耦模块(motion-decoupled module)增强属性解耦的准确性,并训练一个扩散变换器(diffusion transformer)**直接从音频线索生成运动序列。这一阶段专注于运动的生成和解耦。
- 第二阶段: 引入一个情感控制模块(emotion-control module),将情感控制信息编码到潜在空间中。这使得系统能够对表情进行精细控制,从而生成具有所需情感的说话视频。整个过程结合了扩散模型的强大生成能力与3D隐式空间的精细表征能力,以实现高度可控的视频合成。
应用场景
虚拟数字人/AI主播: 创建具有高度表现力和情感的虚拟数字人形象,用于新闻播报、直播、客户服务等。
影视动画制作: 辅助电影、电视或游戏中的角色口型动画和表情生成,提高制作效率和真实感。
个性化内容创作: 用户可以根据需求,生成特定人物、声音和情感的个性化视频内容。
教育培训: 制作生动形象的教育讲解视频,提升学习体验。
语音助手/虚拟客服: 为语音助手或虚拟客服系统提供更加拟人化的视觉交互体验。
Kwai Keye VL 快手
简介
Kwai-Keye专注于多模态大语言模型的前沿探索与创新,致力于推动视频理解、多模态大语言模型等领域的发展。其Keye-VL-8B模型基于Qwen3 - 8B语言模型和SigLIP视觉编码器,在视频理解、复杂逻辑推理等方面表现出色。此外,团队还有多项研究成果,如MM - RLHF、VLM as Policy等。
核心功能
- 多模态交互:支持图像、视频和文本的交互,能对图像和视频进行描述等操作。
- 视频理解:在多个视频基准测试中超越同规模顶级模型。
- 复杂推理:在需要复杂逻辑推理和数学问题解决的评估集中有良好表现。
- 内容审核:如提出的KuaiMod框架可用于短视频平台内容审核。
技术原理
- 模型架构:基于Qwen3 - 8B语言模型,结合从开源SigLIP初始化的视觉编码器,采用3D RoPE统一处理文本、图像和视频信息。
- 预训练:采用四阶段渐进策略,包括图像 - 文本匹配、ViT - LLM对齐、多任务预训练和模型合并退火。
- 后训练:分两个阶段五个步骤,引入混合思维链(CoT)和多思维模式强化学习(RL)机制。
应用场景
智能客服:处理包含图像和视频的用户咨询。
视频平台:视频内容理解、审核和推荐。
教育领域:辅助解决复杂的数学和科学问题。
内容创作:根据图像和视频生成描述和创意内容。
OmniAvatar浙大阿里视频生成
简介
OmniAvatar是一种创新的音频驱动全身视频生成模型,旨在解决现有音频驱动人类动画方法在创建自然同步、流畅的全身动画以及精确提示控制方面的挑战。它引入像素级多层次音频嵌入策略,结合基于LoRA的训练方法,提高了唇同步准确性和身体动作的自然度,在面部和半身视频生成方面超越现有模型,可用于播客、人类交互、动态场景和唱歌等多种领域。
核心功能
- 高质量视频生成:根据单张参考图像、音频和提示,生成具有自适应和自然身体动画的逼真会说话的头像视频。
- 精准唇同步:通过像素级多层次音频嵌入策略,实现音频与唇部动作的精确同步。
- 文本控制:支持精确的基于文本的控制,可控制角色的动作、表情、背景等。
- 身份和时间一致性:利用参考图像嵌入策略保持身份一致,使用潜在重叠策略确保长时间视频生成的时间连续性。
技术原理
- 扩散模型:采用潜在扩散模型(LDM)进行高效视频生成,在潜在空间中逆转扩散过程,将噪声逐步转化为数据。
- 音频嵌入:提出像素级音频嵌入策略,使用Wav2Vec2提取音频特征,通过音频包模块将音频特征映射到潜在空间,并在像素级别嵌入到视频潜在空间。
- LoRA训练:对DiT模型的层应用基于LoRA的训练,在保留基础模型强大功能的同时,有效结合音频作为新条件。
- 长视频生成:利用帧重叠和参考图像嵌入策略,保持长视频生成的一致性和时间连续性。
应用场景
播客制作:生成主播的视频内容,提升播客的视觉效果。
虚拟社交:用于虚拟人物的交互视频,增强社交体验。
动态场景模拟:如游戏、影视等领域,生成角色的动画视频。
音乐表演:生成歌手唱歌的视频,实现音频与动作的同步。
项目链接:
OmniGen2 智源研究院
简介
OmniGen2 是一款多功能开源生成模型,旨在为文本到图像、图像编辑和上下文生成等多种生成任务提供统一解决方案。它具有两条不同的文本和图像模态解码路径,采用非共享参数和分离的图像分词器。研究团队开发了全面的数据构建管道,引入了用于图像生成任务的反射机制和专门的反射数据集。此外,还推出了 OmniContext 基准测试,用于评估模型的上下文生成能力。
核心功能
- 多模态生成:支持文本到图像生成、图像编辑和上下文生成等多种任务。
- 反射机制:能够对生成的图像进行反思,识别不足并迭代优化输出。
- 数据构建:开发了用于图像编辑和上下文生成的数据构建管道,生成高质量数据集。
- 基准测试:引入 OmniContext 基准测试,评估模型在上下文图像生成中的一致性。
技术原理
- 架构设计:采用独立的自回归和扩散变压器架构,使用 ViT 和 VAE 两种不同的图像编码器。
- 位置嵌入:引入 Omni - RoPE 多模态旋转位置嵌入,分解为序列和模态标识符、2D 空间高度和宽度坐标三个组件。
- 训练策略:MLLM 大部分参数冻结,仅更新特殊令牌;扩散模型从头开始训练,采用混合任务训练策略。
- 数据处理:使用多种开源图像数据集进行训练,通过视频数据构建上下文生成和图像编辑数据集。
应用场景
- 创意设计:根据文本描述生成图像,为设计师提供灵感和素材。
- 图像编辑:对现有图像进行修改,如改变背景、移除对象、调整风格等。
- 虚拟现实/增强现实:生成与上下文相关的图像,用于 VR/AR 场景的内容创建。
- 智能客服:根据用户描述生成图像,更直观地回答问题。
FairyGen 动画生成
简介
FairyGen是一个用于从单个儿童手绘角色生成动画故事视频的新颖框架。它借助多模态大语言模型进行故事规划,通过风格传播适配器确保视觉一致性,利用3D代理生成物理上合理的运动序列,并采用两阶段运动定制适配器实现多样化和连贯的视频场景渲染,在风格、叙事和运动方面表现出色。
核心功能
- 故事与分镜规划:利用MLLM从给定角色草图推断结构化分镜,进行时空分镜规划。
- 风格一致背景合成:通过定制风格传播模块,将角色的审美特征传播到背景,生成风格一致的背景。
- 3D代理角色视频序列生成:从2D角色图像重建3D代理,导出物理上合理的运动序列,用于微调图像到视频的扩散模型。
- 两阶段运动定制:第一阶段从无序帧学习外观特征,分离身份和运动;第二阶段使用时间步移策略建模时间动态,生成多样化和连贯的视频场景。
技术原理
- 故事规划:使用MLLM生成结构化分镜,包含全局叙事概述和详细的分镜描述。
- 风格传播:基于预训练的文本到图像扩散模型,采用基于传播的定制策略,在训练时学习角色视觉风格,推理时将其传播到背景。
- 3D重建:从2D草图重建角色的3D代理,导出运动序列,作为训练数据微调MMDiT-based图像到视频扩散模型。
- 两阶段运动定制:第一阶段去除时间偏置,学习空间特征;第二阶段使用时间步移采样策略,增加采样高噪声训练步骤的概率,学习鲁棒的运动表示。
应用场景
教育领域:将儿童绘画转化为动画故事,激发儿童想象力和创造力。
数字艺术治疗:帮助患者通过绘画和动画表达情感和想法。
个性化内容创作:为用户生成个性化的动画故事视频。
互动娱乐:为游戏、动漫等娱乐产业提供创意内容。
论文:FairyGen: Storied Cartoon Video from a Single Child-Drawn Character
HumanOmniV2-阿里
简介
HumanOmniV2 是阿里通义实验室开源的多模态推理模型,解决了多模态推理中全局上下文理解不足和推理路径简单的问题。它能在生成答案前分析视觉、听觉和语言信号,构建场景背景,精准捕捉隐藏逻辑和深层意图。该模型在 IntentBench 等基准测试中表现出色,现已开源。
核心功能
- 全面理解多模态信息:综合分析图像、视频、音频等多模态输入,捕捉隐藏信息和深层逻辑。
- 精准推理人类意图:基于上下文背景,准确理解对话或场景中的真实意图。
- 生成结构化推理路径:输出详细的上下文总结和推理步骤,确保推理可解释。
- 应对复杂社交场景:识别理解人物情绪、动机及社会关系,提供符合人类认知的判断。
技术原理
- 强制上下文总结机制:输出 context标签内的上下文概括,构建完整场景背景。
- 大模型驱动的多维度奖励体系:包含上下文、格式、准确性和逻辑奖励,激励模型准确推理。
- 基于 GRPO 的优化训练方法:引入词元级损失,移除问题级归一化项,应用动态 KL 散度机制。
- 高质量的全模态推理训练数据集:包含图像、视频和音频任务,附带详细标注。
- 全新的评测基准 IntentBench:评估模型对人类行为动机、情感状态和社会互动的理解能力。
应用场景
- 视频内容理解与推荐:为视频平台提供精准推荐。
- 智能客服与客户体验优化:帮助客服人员应对客户问题。
- 情感识别与心理健康支持:辅助心理健康应用提供情绪支持。
- 社交互动分析与优化:优化社交推荐和用户互动体验。
- 教育与个性化学习:为在线教育平台提供个性化学习建议。
通义万相2.2 – 阿里开源AI视频生成模型
简介
通义万相(Tongyi Wanxiang)是阿里云通义旗下的人工智能创意创作平台。其中,通义万相2.2(Wan2.2)是阿里巴巴开源的先进AI视频生成模型,旨在降低创意工作的门槛。该平台集成了多种AI生成能力,包括视频和图像内容的创作。
核心功能
- 文生视频(Text-to-Video, T2V): 根据文本描述生成视频内容。
- 图生视频(Image-to-Video, I2V): 根据静态图片生成动态视频。
- 统一视频生成(Unified Video Generation, IT2V): 整合文本和图像输入进行视频生成。
- 图像生成: 支持文生图、图生图、涂鸦作画、虚拟模特、个人写真等多种图像创作模式。
- 高级特效与LoRA训练: 提供增强的图像/视频生成效果和更智能的LoRA模型训练功能。
- 电影级控制: 首次实现MoE架构的视频生成模型,具备电影级控制能力。
技术原理
通义万相2.2基于先进的AI视频生成模型,采用大规模模型(Large-Scale Video Generative Models)和混合专家架构(MoE-Architecture)来提升视频生成质量和控制力。其核心技术可能包括深度学习、扩散模型(如Hugging Face上提及的Diffusers)以及复杂的神经网络结构,以实现从文本或图像到高质量视频的转换。
应用场景
内容创作: 为电影、广告、短视频等领域的创作者提供高效的视频和图像生成工具,降低制作成本和时间。
数字营销: 快速生成个性化、吸引人的宣传视频和图片,用于产品推广和品牌建设。
艺术设计: 辅助艺术家和设计师进行概念验证和视觉化创作,拓宽创意边界。
个人娱乐: 满足普通用户生成有趣视频和图片的个性化需求,如社交媒体分享等。
教育与培训: 制作教学动画、演示视频,提升学习体验。
腾讯混元3D世界模型开源
简介
Hunyuan3D是腾讯研发的大规模三维生成模型,基于先进的扩散(Diffusion)技术。它能够通过文本描述或图像输入,快速、高效地生成高质量、逼真的3D资产。HunyuanWorld-1.0作为其重要组成部分,更是首个开源的三维世界生成模型,旨在革新3D内容创作流程。

核心功能
- 文本到三维生成 (Text-to-3D Generation):依据自然语言描述直接生成多样化的3D模型,涵盖物体、角色、环境等。
- 图像到三维重建 (Image-to-3D Reconstruction):将2D图像转换为具有精确几何和纹理的高质量3D模型。
- 高分辨率与高质量输出 (High-Resolution & High-Quality Output):生成细节丰富、视觉效果出众的3D资产。
- 多视图生成与重建 (Multi-view Generation & Reconstruction):支持从多角度图像输入进行3D模型的生成与精细重建。
- 场景与世界生成 (Scene & World Generation):尤其通过HunyuanWorld-1.0,实现复杂三维场景乃至整个虚拟世界的自动化生成。
技术原理
Hunyuan3D的核心技术是扩散模型 (Diffusion Models),这是一种生成式AI模型,通过逐步去噪过程从随机噪声中学习数据分布并生成新样本。其架构包含:
- 文本编码器 (Text Encoders):负责将输入的文本描述转换为高维语义特征。
- 图像编码器 (Image Encoders):处理输入的2D图像,提取视觉特征。
- 扩散模型 (Diffusion Models):接收编码后的文本或图像特征,通过多步迭代逆向扩散过程,逐步从噪声中恢复并生成3D的潜在表示。
- 3D解码器 (3D Decoders):将扩散模型输出的3D潜在表示解码为最终的3D几何(如网格或体素)和纹理信息,完成从2D/文本到3D的映射。
- 整个系统通过大规模3D数据集进行训练,以确保生成内容的质量和多样性。
应用场景
- 游戏开发 (Game Development):快速生成游戏角色、道具、场景环境,显著提升内容创作效率。
- 影视动画制作 (Film & Animation Production):辅助制作复杂的3D场景、特效及角色,降低生产成本和周期。
- 虚拟现实 (VR) 与增强现实 (AR):为VR/AR应用提供丰富的3D内容库,构建沉浸式体验。
- 数字内容创作 (Digital Content Creation):赋能设计师、艺术家和内容创作者,快速实现3D视觉创意。
- 元宇宙构建 (Metaverse Construction):大规模生成虚拟世界的3D资产和环境,加速元宇宙生态的建设。
- 产品设计与可视化 (Product Design & Visualization):将概念图或文本描述迅速转化为3D模型进行展示、原型制作和评估。
腾讯混元 3D 世界模型 1.0:
- 项目主页:https://3d-models.hunyuan.tencent.com/world/
- 体验地址:https://3d.hunyuan.tencent.com/sceneTo3D
- Hugging Face 模型地址:https://huggingface.co/tencent/HunyuanWorld-1
- Github 项目地址:https://github.com/Tencent-Hunyuan/HunyuanWorld-1.0
书生浦语-科学多模态大模型Intern-S1
简介
Intern-S1 是上海人工智能实验室 (Shanghai AI Laboratory) 开发的 InternLM 系列大型语言模型 (LLM) 中的一员。它旨在提供高质量的语言模型和全栈工具链,尤其强调其强大的推理能力和与外部工具的交互能力。
核心功能
- 工具调用 (Tool Calling):能够调用外部工具,例如获取实时信息、执行代码或调用其他应用程序内的函数,从而扩展模型的能力边界。
- 思维模式 (Thinking Mode):默认开启的思维模式显著增强了模型的推理能力,使其能够生成更高质量的响应。此模式可根据需要进行配置。
- 多模态能力 (Multimodal Capabilities):支持多模态输入,进一步拓宽了模型的应用范围。
技术原理
Intern-S1 基于 InternLM 的基础架构,并在此基础上进行了优化:
- 函数调用集成:通过特定的工具调用机制,模型能够解析用户意图并自动选择、调用外部函数或API,将外部世界的信息和能力整合到其响应生成过程中。
- FP8 量化:提供 FP8 (8位浮点) 量化版本,这意味着模型在保持较高性能的同时,大幅降低了显存占用和计算资源需求,提高了推理效率。
- 高级推理机制:内置"思维模式",通过引导模型进行类似人类的逐步思考过程,提升其复杂问题的推理和解决能力。
- 部署灵活性:支持通过 SGLang 和 Ollama 等多种方式进行本地部署,为开发者和研究人员提供了便捷的实验和应用环境。
应用场景
智能代理 (AI Agents):构建能够自主获取最新信息、执行复杂任务或与外部系统交互的智能代理。
代码辅助与自动化:在软件开发中,辅助代码生成、调试,或自动化某些编程任务。
实时信息查询:结合外部搜索引擎或数据库,提供即时、准确的信息服务。
复杂问题解决:在需要多步推理和外部工具协助的领域(如科学计算、金融分析)提供解决方案。
大模型研究与开发:作为开放的模型和工具链,为研究人员和开发者提供强大的基础模型和开发平台,用于探索新的应用和优化。
Github仓库:https://github.com/InternLM/Intern-S1
HuggingFace模型库:https://huggingface.co/internlm/Intern-S1-FP8
官网:https://intern-ai.org.cn/home
Step 3 – 阶跃星辰多模态推理模型
简介
Step 3 是阶跃星辰(StepFun AI)发布的新一代基础大模型,专为推理时代设计。它集高性能与极致成本效益于一体,具备强大的视觉感知和复杂推理能力,旨在成为SOTA(State-of-the-Art)水平的开放生态基础模型。
核心功能
- 多模态感知与理解: 具备强大的视觉感知能力,能处理和理解多种模态的信息。
- 复杂推理: 针对推理时代的需求,擅长进行复杂的逻辑推理。
- 高性能与高效率: 在保证卓越性能的同时,注重极致的成本效益。
- 开放生态支持: 作为开放模型,支持开发者和研究人员在其基础上进行创新。
技术原理
Step 3 采用了先进的MoE(Mixture-of-Experts)架构,这使得模型能够在大参数量下实现高效的激活参数量,从而平衡性能与计算资源消耗。总参数量达到321B,激活参数量为38B。这种架构有助于模型在不同任务上动态激活最相关的专家网络,优化资源利用和推理效率。其技术报告进一步详细阐述了Attention-FFN解耦等优化技术,以实现高吞吐量解码。
应用场景
智能助理与对话系统: 提供更自然、智能的多模态交互体验。
视觉内容理解与生成: 应用于图像识别、视频分析、内容创作等领域。
复杂问题解决: 在科研、工程、医疗等需要强大推理能力的场景中提供辅助。
开发者工具与平台: 作为基础模型,可供开发者在其上构建各类AI应用和服务。
Github仓库:https://github.com/stepfun-ai/Step3
Higgs Audio V2 – 开源语音大模型
简介
Higgs Audio V2是由李沐及其团队Boson AI开发并开源的语音大模型。它是一个强大的音频基础模型,经过超过1000万小时的音频数据和多样化文本数据的预训练,旨在模拟自然流畅的多人互动场景,并具备生成高质量音频的能力。
核心功能
- 多语言对话生成: 能够生成自然流畅的多语言对话。
- 自动韵律调整: 自动匹配说话者的韵律和情感。
- 语音克隆: 具备语音克隆能力,可以复制特定人的声音。
- 歌声合成: 支持歌声合成功能。
- 零样本文本到语音(Zero-shot TTS): 能够在没有特定训练数据的情况下,通过参考文本、参考音频和目标文本进行文本到语音的转换。
- 多人对话生成: 特别优化了模拟多人互动对话场景的能力。
技术原理
Higgs Audio V2采用统一的音频语言建模方法(unified audio language modeling at scale)。它是一个基于超过1000万小时的音频数据和多样化文本数据进行预训练的音频基础模型。这种大规模的预训练使其能够捕捉复杂的语音特征、韵律变化以及多语言和多说话人的交互模式,从而实现自然度高、表现力强的语音生成。模型在多个基准测试中展现出高性能,包括Seed-TTS Eval、Emotional Speech Dataset (ESD)、EmergentTTS-Eval和Multi-speaker Eval。
应用场景
虚拟助手与客服系统: 创建更自然、更具交互性的AI虚拟助手和智能客服。
内容创作: 用于播客、有声读物、游戏配音、动画等领域,快速生成高质量的语音和对话内容。
教育与培训: 制作多语言教学材料、模拟对话练习,提升学习体验。
电影与电视制作: 辅助角色配音,实现不同角色间的自然对话,甚至进行歌声合成。
无障碍辅助: 为有视力障碍的用户提供文本转语音服务,或为特定应用提供定制化语音交互。
社交媒体与娱乐: 生成个性化的音频内容,增强用户互动体验,如语音社交、虚拟偶像歌唱等。
Github仓库:https://github.com/boson-ai/higgs-audio
在线体验Demo:https://huggingface.co/spaces/smola/higgs_audio_v2
AudioGen-Omni – 快手推出的多模态音频生成框架
简介
AudioGen-Omni是快手推出的一款多模态音频生成框架,能够基于视频、文本等多种输入,高效生成高质量的音频、语音和歌曲。它旨在提供一个统一的解决方案,以满足不同形式的音频内容创作需求。
核心功能
- 多模态输入支持: 能够接受视频和文本作为输入,生成相应的音频内容。
- 高保真音频生成: 可生成高质量的背景音乐、语音、环境音效以及完整歌曲。
- 统一生成能力: 框架实现了对不同类型音频(如语音、音乐、音效)的统一生成,简化了工作流程。
技术原理
AudioGen-Omni基于多模态扩散Transformer (MMDit) 架构,通过联合训练大规模的视频-文本-音频语料库进行学习。其核心技术包括统一的歌词-文本编码器,以及用于相位对齐的先进机制(如AdaLN),确保生成音频的连贯性和质量。这种架构使其能够理解复杂的跨模态信息,并生成与输入高度相关的音频。
应用场景
- 短视频及直播内容创作: 为视频自动配乐、生成旁白或特效声音,提升内容丰富度。
- 音乐制作与歌曲创作: 从文本歌词或意图描述生成歌曲旋律、伴奏及人声。
- 智能语音助手与虚拟人: 生成自然流畅的语音对话,增强人机交互体验。
- 多媒体内容编辑: 作为AI辅助工具,帮助用户快速生成所需的音频素材。
AudioGen-Omni的项目地址
- 项目官网:https://ciyou2.github.io/AudioGen-Omni/
- arXiv技术论文:https://ciyou2.github.io/AudioGen-Omni/
MiDashengLM – 小米开源的高效声音理解大模型
简介
MiDaShengLM-7B是小米研究(Xiaomi Research)开源的多模态语音AI模型,参数规模为70亿,专注于音频理解和推理。该模型旨在通过整合先进的音频编码器和大型语言模型,实现对语音、环境声音和音乐元素的全面理解。它代表了小米在语音AI领域的重要进展,并已面向全球社区开放。
核心功能
- 通用音频理解与推理: 能够综合理解和推理各种音频内容,包括人类语音、环境声音(如硬币掉落、水滴声)和音乐元素。
- 跨模态融合: 有效结合音频输入与文本提示,生成相关的文本响应,支持音频到文本的理解。
- 高效推理: 相较于同类模型(如Qwen2.5-Omni-7B),展现出卓越的推理效率和更快的响应时间,即使在处理较长音频输入时也能保持性能。
- 情绪与音乐理解: 具备理解说话者情绪和音乐的能力,超越了传统语音识别的范畴。
技术原理
MiDaShengLM-7B的核心技术原理是其独特的集成架构:
- Dasheng音频编码器: 采用了小米自研的Dasheng开源音频编码器,该编码器以其在通用音频理解方面的先进性能而闻名。
- Qwen2.5-Omni-7B Thinker解码器: 与阿里巴巴的Qwen2.5-Omni-7B Thinker解码器进行集成,实现强大的语言理解和生成能力。
- 基于字幕的对齐策略(Caption-based Alignment Strategy): 模型采用独特的基于字幕的对齐策略,利用通用音频字幕来捕捉全面的音频表示。这种方法不同于传统的ASR驱动方法,能更有效地整合语音、环境声音和音乐,形成统一的文本表示。
- 端到端自主信息检索与多步推理: 结合了类似AI Agent的能力,使其能够在复杂的音频环境中进行主动感知、决策和行动,进行深度的信息检索和多步推理。
应用场景
- 智能家居: 作为智能设备的核心语音交互模块,实现更自然、智能的语音控制和环境感知。
- 汽车领域: 在智能驾驶舱中提供高级语音助手功能,包括语音命令识别、环境噪音过滤和情绪识别。
- 通用AI应用: 广泛应用于需要音频理解和跨模态交互的各种AI产品和框架中,如智能助手、内容创作、安防监控等。
- 音频内容分析: 对播客、音乐、环境录音等进行深度分析,提取关键信息和情感。
- 残障辅助技术: 通过更准确地理解和响应音频输入,提升相关辅助设备的性能。
MiDashengLM的项目地址
- GitHub仓库:https://github.com/xiaomi-research/dasheng-lm
- HuggingFace模型库:https://huggingface.co/mispeech/midashenglm-7b
- 技术论文:https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- 在线体验Demo:https://huggingface.co/spaces/mispeech/MiDashengLM-7B
RynnVLA-001 – 阿里达摩院开源的视觉-语言-动作模型
RynnVLA-001是阿里巴巴达摩院开发的一种视觉-语言-动作(Vision-Language-Action, VLA)模型。该模型通过大规模第一人称视角的视频进行预训练,旨在从人类示范中学习操作技能,并能够将这些技能隐式地迁移到机器人手臂的控制中,使其能够理解高层语言指令并执行复杂的任务。
核心功能
- 视觉-语言理解与融合: 能够理解视觉输入和自然语言指令,并将两者关联起来。
- 技能学习与迁移: 从人类第一人称视角的视频示范中学习复杂的操作技能,并将其迁移到机器人平台。
- 机器人操作控制: 使机器人手臂能够精确执行抓取-放置(pick-and-place)等复杂操作任务。
- 长程任务执行: 支持机器人根据高级语言指令完成需要多步操作的长程任务。
技术原理
RynnVLA-001的核心技术原理是基于生成式先验(generative priors)构建的。它是一个简单而有效的VLA模型,其基础是一个预训练的视频生成模型。具体流程包括:
- 第一阶段:自我中心视频生成模型(Ego-centric Video Generation Model): 利用大量第一人称视频数据训练一个视频生成模型,捕捉人类操作的视觉规律。
- 第二阶段:机器人动作块的VAE压缩(VAE for Compressing Robot Action Chunks): 使用变分自编码器(VAE)对机器人动作序列进行高效压缩,提取核心动作特征。
- 第三阶段:视觉-语言-动作模型构建(Vision-Language-Action Model): 将视频生成模型和动作VAE结合,构建一个端到端的VLA模型,使其能够从视觉和语言输入中直接生成机器人动作。
应用场景
机器人工业自动化: 用于训练工业机器人执行精细装配、分拣和搬运等任务,提高生产线自动化水平。
服务机器人: 赋予服务机器人更强的环境感知和人机交互能力,使其能更好地理解并执行用户指令,例如家庭助手、医疗辅助机器人。
人机协作: 促进机器人更自然地与人类协作,通过观察人类操作学习新技能,提高协作效率。
智能家居: 应用于智能家电和自动化系统中,实现更智能、更人性化的设备控制和任务执行。
教育与研究: 为机器人学习、多模态AI等领域提供一个强大的研究平台和教学工具。
项目官网:https://huggingface.co/blog/Alibaba-DAMO-Academy/rynnvla-001
GitHub仓库:https://github.com/alibaba-damo-academy/RynnVLA-001
HuggingFace模型库:https://huggingface.co/Alibaba-DAMO-Academy/RynnVLA-001-7B-Base
Matrix-3D – 昆仑万维开源的3D世界模型
Matrix-3D是由昆仑万维Skywork AI团队开发的一个先进框架,旨在通过单张图像或文本提示生成可探索的大规模全景3D世界。它结合了全景视频生成与3D重建技术,旨在实现高保真、全向可探索的沉浸式3D场景。
核心功能
- 全景3D世界生成: 能够从单一图像或文本提示生成广阔且可探索的全景3D场景。
- 图像/文本到3D场景转换: 支持将输入的图像或文本描述直接转化为对应的3D世界内容。
- 条件视频生成: 具备基于特定条件生成全景视频的能力。
- 全景3D重建: 实现对全景图像或视频内容的3D重建。
- 强大的泛化能力: 基于自研的3D数据和视频模型先验,能够生成多样化且高质量的3D场景。
技术原理
Matrix-3D的核心技术原理在于其对**全景表示(panoramic representation)**的利用,以实现广覆盖、全向可探索的3D世界生成。它融合了以下关键技术:
- 条件视频生成(conditional video generation): 通过深度学习模型,根据输入条件(如图像或文本)生成符合要求的全景视频序列。
- 全景3D重建(panoramic 3D reconstruction): 运用计算机视觉和图形学技术,从全景图像或视频中恢复场景的几何信息和结构。
- 3D数据和视频模型先验(3D data and video model priors): 模型在大量自研的3D数据和视频数据上进行训练,学习到丰富的场景结构和动态规律,从而增强了生成结果的真实感和多样性。
应用场景
- 虚拟现实(VR)/增强现实(AR)内容创作: 快速生成沉浸式的VR/AR环境,用于游戏、教育、旅游等领域。
- 元宇宙(Metaverse)构建: 为元宇宙平台提供大规模、可探索的3D场景内容生成能力。
- 影视动画制作: 辅助制作人员快速生成复杂的3D场景背景或预览。
- 虚拟漫游与规划: 在房地产、城市规划、室内设计等领域,用于生成虚拟漫游体验。
- 数字孪生(Digital Twin): 构建现实世界的虚拟副本,进行模拟和分析。
- 游戏开发: 提升游戏场景的生成效率和多样性,实现更加生动逼真的游戏世界。
Matrix-3D的项目地址
- 项目官网:https://matrix-3d.github.io/
- GitHub仓库:https://github.com/SkyworkAI/Matrix-3D
- HuggingFace模型库:https://huggingface.co/Skywork/Matrix-3D
- 技术论文:https://github.com/SkyworkAI/Matrix-3D/blob/main/asset/report.pdf
Matrix-Game 2.0 – 昆仑万维推出的自研世界模型
Matrix-Game 2.0是由昆仑万维SkyWork AI发布的一款自研世界模型,被誉为业内首个开源的通用场景实时长序列交互式生成模型。它旨在推动交互式世界模型领域的发展,能够实现可控的游戏世界生成,并支持高质量、实时、长序列的视频生成。
核心功能
- 交互式世界生成: 能够根据指令生成和操控游戏世界,实现高度交互性。
- 实时长序列视频生成: 以25 FPS的超高速率生成分钟级的高质量视频,支持多样的场景。
- 基础世界模型: 作为交互式世界的基础模型,参数量达到17B,可用于构建复杂的虚拟环境。
- 全面开源: 提供模型权重和相关资源,促进社区共同发展和应用。
技术原理
- 生成对抗网络 (GAN) 或扩散模型 (Diffusion Models): 用于高质量的图像和视频内容生成。
- 序列建模: 采用Transformer等架构处理长序列的交互和状态变化,以实现实时且连贯的世界演进。
- 强化学习 (Reinforcement Learning) 或模仿学习 (Imitation Learning): 用于训练模型理解用户意图并生成可控的交互行为。
- 多模态融合: 结合视觉、文本、动作等多种模态信息,以构建更丰富的世界表征。
- 高效推理优化: 实现25 FPS的实时生成速度,可能采用了量化、剪枝或并行计算等优化技术。
应用场景
具身AI训练: 为具身智能体提供逼真且可控的训练环境。
虚拟现实/元宇宙构建: 快速生成和定制虚拟世界内容,提升用户体验。
游戏开发: 自动化游戏场景、角色行为和故事情节的生成,大幅提高开发效率。
数字孪生: 创建真实世界的虚拟复刻,用于模拟、预测和优化。
内容创作: 辅助艺术家和设计师进行概念设计、动画制作和电影预可视化。
项目官网:https://matrix-game-v2.github.io/
GitHub仓库:https://github.com/SkyworkAI/Matrix-Game
HuggingFace模型库:https://huggingface.co/Skywork/Matrix-Game-2.0
技术报告:https://github.com/SkyworkAI/Matrix-Game/blob/main/Matrix-Game-2/assets/pdf/report.pdf
GLM-4.5V – 智谱开源的最新一代视觉推理模型
GLM-4.5V是由智谱AI开发并开源的领先视觉语言模型(VLM),它基于智谱AI新一代旗舰文本基座模型GLM-4.5-Air(总参数1060亿,活跃参数120亿)。该模型继承并发展了GLM-4.1V-Thinking的技术路线,旨在提升多模态感知之上的高级推理能力,以解决复杂AI任务,并支持长上下文理解和多模态智能体应用。
核心功能
- 多模态理解与感知: 能够处理和理解图像、视频、文档等多源异构数据。
- 高级推理能力: 具备强大的长上下文理解、科学问题解决(STEM Reasoning)和代理(Agentic)能力。
- 代码与GUI操作: 支持代码理解、生成以及图形用户界面(GUI)的自动化操作。
- 工具调用: 支持函数调用、知识库检索和网络搜索等工具集成。
- 混合推理模式: 提供"思考模式"用于复杂推理和工具使用,以及"非思考模式"用于即时响应。
技术原理
GLM-4.5V的技术核心在于其 “思考模式”(Thinking Mode) 和 多模态强化学习(Multimodal Reinforcement Learning, RL)。它基于大规模Transformer架构,以GLM-4.5-Air作为其文本基础模型。通过采用GLM-4.1V-Thinking的先进方法,模型在多模态数据上进行了大规模训练,并结合可扩展的强化学习策略,显著增强了其复杂问题解决、长上下文处理和多模态代理能力。模型响应中的边界框(Bounding Box)坐标通过特殊标记<|begin_of_box|>和<|end_of_box|>表示,坐标值通常在0到1000之间归一化,用于视觉定位。
应用场景
智能助理与Agent: 构建能够执行复杂多模态任务的智能代理,如内容创作、信息检索、自动化流程。
教育与研究: 辅助科学、技术、工程、数学(STEM)领域的复杂问题求解。
文档处理与分析: 进行长文档理解、内容识别与提取。
自动化测试与操作: 实现基于GUI的应用程序自动化操作,如UI测试、任务执行。
多媒体内容分析: 应用于图像和视频内容理解、分析与生成。
编码辅助: 作为代码助手,进行代码理解和生成。
GitHub仓库:https://github.com/zai-org/GLM-V/
HuggingFace模型库:https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102
技术论文:https://github.com/zai-org/GLM-V/tree/main/resources/GLM-4.5V_technical_report.pdf
桌面助手应用:https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
Skywork UniPic 2.0 – 昆仑万维开源的统一多模态模型
简介
Skywork UniPic 2.0 是昆仑万维开源的高效多模态模型,致力于实现统一的图像生成、编辑和理解能力。该模型旨在通过统一的架构处理视觉信息,提升多模态任务的效率和性能。
核心功能
- 图像生成: 能够根据文本描述或其他输入生成高质量图像。
- 图像编辑: 提供对图像内容的编辑和修改能力。
- 图像理解: 具备对图像进行语义理解和分析的能力。
- 统一多模态处理: 将图像生成、编辑和理解等功能集成在一个模型框架内,实现多任务处理。
技术原理
Skywork UniPic 2.0 基于2B参数的SD3.5-Medium架构(部分资料提及UniPic为1.5B参数的自回归模型,但2.0版本主要强调SD3.5-Medium架构)。其核心技术原理包括:
- 自回归模型(Autoregressive Model): 通过预测序列中的下一个元素来逐步生成内容,尤其在图像生成和理解中表现出强大能力。
- 多模态预训练: 模型通过大规模多模态数据进行预训练,学习图像与文本之间的深层关联。
- 渐进式双向特征融合: 采用先进的特征融合技术,有效整合不同模态的信息,增强模型的跨模态理解与生成能力。
- 统一表示学习: 旨在学习一种统一的视觉和文本表示,使得模型能够在一个共享的潜在空间中进行多模态任务处理。
应用场景
内容创作: 辅助设计师、艺术家和营销人员快速生成创意图像、广告素材等。
图像处理与分析: 在图像编辑软件中集成,实现智能图像修复、风格迁移或内容修改;在安防、医疗等领域进行图像识别和分析。
多模态交互系统: 作为智能助手或聊天机器人的一部分,支持用户通过自然语言进行图像查询、生成和编辑。
教育与研究: 为多模态AI领域的研究人员提供开源模型和工具,推动技术发展和创新应用。
项目官网:https://unipic-v2.github.io/
GitHub仓库:https://github.com/SkyworkAI/UniPic/tree/main/UniPic-2
HuggingFace模型库:https://huggingface.co/collections/Skywork/skywork-unipic2-6899b9e1b038b24674d996fd
技术论文:https://github.com/SkyworkAI/UniPic/blob/main/UniPic-2/assets/pdf/UNIPIC2.pdf
项目官网:https://unipic-v2.github.io/
GitHub仓库:https://github.com/SkyworkAI/UniPic/tree/main/UniPic-2
HuggingFace模型库:https://huggingface.co/collections/Skywork/skywork-unipic2-6899b9e1b038b24674d996fd
技术论文:https://github.com/SkyworkAI/UniPic/blob/main/UniPic-2/assets/pdf/UNIPIC2.pdf
Voost – 创新的双向虚拟试穿和试脱AI模型
Voost 是由 Seungyong Lee 和 Jeong-gi Kwak (来自 NXN Labs) 共同开发的一个统一且可扩展的扩散变换器 (Diffusion Transformer) 框架。它旨在解决虚拟试穿中服装与身体对应关系建模的挑战,并首次将虚拟试穿 (Virtual Try-On) 和虚拟脱衣 (Virtual Try-Off) 功能整合到单一模型中,实现了双向处理,显著提高了虚拟服装合成的真实性和泛化能力。
核心功能
- 统一的虚拟试穿与脱衣: 在一个模型中同时支持虚拟试穿(将服装穿到人体上)和虚拟脱衣(将服装从人体上移除)功能。
- 高保真图像合成: 生成高度逼真的人体穿着或脱下目标服装的图像。
- 鲁棒性: 能够适应不同的人体姿态、服装类别、背景、光照条件和图像构图,保持高质量输出。
- 双向监督学习: 通过联合建模试穿和脱衣任务,利用服装-人体对在两个方向上进行监督,提高模型的准确性和灵活性。
- 可扩展性: 作为一个统一且可扩展的框架,具有良好的性能和应用潜力。
技术原理
Voost 的核心技术是其提出的"统一且可扩展的扩散变换器 (Unified and Scalable Diffusion Transformer)"。该模型利用扩散模型 (Diffusion Model) 在图像生成方面的强大能力,结合变换器架构 (Transformer Architecture) 处理序列和长距离依赖的优势,以端到端的方式学习虚拟试穿和脱衣的复杂映射关系。通过一个单一的扩散变换器,Voost 能够:
- 联合学习: 同时编码和解码人体与服装之间的复杂交互,实现试穿和脱衣任务的协同优化。
- 细节建模: 扩散模型逐步去噪的特性使其能够生成高分辨率且细节丰富的图像,精确模拟服装的褶皱、纹理和与身体的贴合。
- 变换器架构: 使得模型能够捕捉图像中不同区域(如人体姿态、服装形状、背景信息)之间的全局依赖关系,增强了模型处理复杂场景的能力和泛化性。
- 双向流: 实现从服装到人体的合成 (Try-On) 和从人体到服装的逆向合成 (Try-Off),从而在训练中提供更丰富的监督信号,提升模型对服装-身体对应关系的理解。
应用场景
在线虚拟试穿平台: 消费者可以在线预览服装穿着效果,提高购物体验和决策效率。
服装设计与制造: 设计师快速验证服装设计在不同人体模型上的效果,加速设计迭代周期。
时尚内容创作: 快速生成高质量的时尚宣传图片或视频,用于广告、社交媒体等。
虚拟现实/增强现实: 为元宇宙、虚拟形象和游戏中的服装更换提供技术支持。
个性化推荐系统: 结合用户身体特征和偏好,推荐最适合的服装并展示虚拟试穿效果。
项目官网:https://nxnai.github.io/Voost/
Github仓库:https://github.com/nxnai/Voost
arXiv技术论文:https://arxiv.org/pdf/2508.04825
Qwen-Image-Edit
Qwen-Image-Edit 是由阿里通义(Qwen)团队推出的全能图像编辑模型,其核心构建于200亿参数的Qwen-Image架构之上。该模型融合了语义与外观层面的双重编辑能力,旨在提供精确、高效的图像内容修改。
核心功能
- 语义级图像编辑: 能够理解并修改图像中的概念、对象或场景,实现高层次的内容调整。
- 外观级图像编辑: 支持对图像的低层次视觉细节进行编辑,如添加、删除元素或调整视觉风格。
- 双语文本精准编辑: 具备对图片内中英文文本进行精确修改的能力,同时保持原图风格一致性。
技术原理
Qwen-Image-Edit 基于大型预训练的视觉-语言模型(VLMs)——Qwen-Image,该模型拥有200亿参数,使其具备强大的图像理解与生成能力。其实现双重编辑能力可能采用了多模态融合技术,结合扩散模型(Diffusion Models)进行高质量图像生成与编辑,并通过条件控制机制(如文本提示、掩码)来引导编辑过程。针对文本编辑,模型可能利用了其多语言理解能力,结合图像内容上下文进行文本嵌入、渲染及融合,以确保编辑的自然性和风格保持。
应用场景
专业内容创作: 辅助设计师、营销人员快速修改图像素材,满足广告、社交媒体等需求。
个性化图像处理: 用户可以利用其进行高级的个人照片编辑,实现定制化效果。
电子商务与产品展示: 快速调整商品图片,如修改产品标签、文字说明或细节展示。
智能图像辅助: 在办公、教育等场景中,实现对图片信息的快速修改与更新。
学术研究与开发: 作为图像编辑领域的基础模型,可用于进一步的算法研究与应用探索。
项目官网:https://qwenlm.github.io/blog/qwen-image-edit/
GitHub仓库:https://github.com/QwenLM/Qwen-Image
HuggingFace模型库:https://huggingface.co/Qwen/Qwen-Image-Edit
在线体验Demo:https://huggingface.co/spaces/Qwen/Qwen-Image-Edit
ToonComposer – 腾讯联合港中文、北大推出的AI动画制作工具
ToonComposer是由腾讯ARC实验室开发的一款生成式AI工具,旨在彻底改变和简化传统的卡通及动漫制作流程。它主要通过自动化关键帧之间的中间帧生成(inbetweening)工作,极大地提高了动画制作效率,减少了人工工作量。
核心功能
- 自动化中间帧生成: 能够根据用户输入的草图关键帧,智能地生成完整的动画帧序列,填补关键帧之间的空隙。
- 高效率与成本节约: 显著节省约70%的人工工作量,加速动画制作周期。
- 精确控制: 提供对草图关键帧的精确控制能力,允许用户精细调整动画效果。
- 智能填充与区域控制: 支持智能图像填充和特定区域的精细化控制,确保生成内容的质量和一致性。
技术原理
ToonComposer采用先进的生成式人工智能(Generative AI)技术,特别是通过"生成式关键帧后处理"(Generative Post-Keyframing)方法来驱动动画帧的生成。其核心在于利用深度学习模型理解关键帧间的运动和形态变化,并自主合成中间帧,从而实现动画的平滑过渡。这一技术统一了传统的动画插帧过程,摆脱了对每一帧手动绘制的依赖。
应用场景
- 卡通动画制作: 广泛应用于卡通片、动漫剧集的制作,特别是在需要大量中间帧的场景。
- 电影与游戏动画: 可用于影视特效和游戏动画的预制作或辅助制作,提高生产效率。
- 个人创作者与小型工作室: 赋能独立动画师和小型团队,降低动画制作的技术门槛和成本。
- 教育与研究: 作为AI在内容创作领域应用的案例,可用于相关领域的教学和研究。
ToonComposer的项目地址
- 项目官网:https://lg-li.github.io/project/tooncomposer/
- GitHub仓库:https://github.com/TencentARC/ToonComposer
- HuggingFace模型库:https://huggingface.co/TencentARC/ToonComposer
- arXiv技术论文:https://arxiv.org/pdf/2508.10881
- 在线体验Demo:https://huggingface.co/spaces/TencentARC/ToonComposer
混元3D世界模型1.0推出Lite版本
腾讯混元世界模型1.0(Hunyuan World Model 1.0)是腾讯发布的一款基于AI的开源3D场景生成模型。它能够将文本描述或单张图片快速转化为高质量、可探索、360度的沉浸式3D虚拟世界,极大地简化了传统3D内容创作的复杂流程,实现分钟级生成。
核心功能
- 文本/图像到3D场景生成: 能够根据文字指令或图片输入,自动生成完整的3D场景。
- 360度可探索环境: 生成的场景支持360度全景视图,并具有可探索性。
- 标准格式输出: 生成的3D内容可导出为标准网格文件(如Mesh),兼容主流游戏引擎和CG软件。
- 高生成质量: 在纹理细节、真实感、美学质量和指令遵循方面表现出色。
- 内容编辑能力: 支持对前景物体进行调整以及替换天空背景,满足个性化创作需求。
技术原理
腾讯混元世界模型1.0的生成架构核心在于结合了多项先进技术:
- 全景代理生成: 实现全景图像的合成。
- 语义分层: 对场景中的元素进行语义理解和分层处理。
- 分层3D重建: 通过分层结构对场景进行高精度3D重建,确保场景的深度和结构准确性。
- AIGC技术: 综合运用人工智能生成内容技术,自动化复杂的3D建模过程。
应用场景
游戏开发: 快速生成游戏原型、关卡设计所需的3D场景、建筑、地形和植被等元素。
虚拟现实(VR)/元宇宙内容创作: 为VR体验和虚拟世界构建提供沉浸式3D环境。
影视动画制作: 作为辅助工具,加速场景的搭建和概念验证。
数字艺术与设计: 帮助设计师和艺术家快速实现创意,无需专业的3D建模技能。
教育与模拟: 创建逼真的3D环境用于教学、训练和模拟。
传统CG工作流集成: 支持与现有计算机图形工作流的无缝衔接,进行编辑和物理仿真。
官网地址:https://3d.hunyuan.tencent.com/sceneTo3D
Github 项目地址:https://github.com/Tencent-Hunyuan/HunyuanWorld-1.0
Hugging Face模型地址:https://huggingface.co/tencent/HunyuanWorld-1
技术报告地址:https://arxiv.org/abs/2507.21809
DINOv3 – Meta开源的通用视觉基础模型
DINOv3是Meta AI推出的一款通用、SOTA(State-of-the-Art)级视觉基础模型,通过大规模自监督学习(SSL)进行训练。它能够从无标注数据中学习并生成高质量的高分辨率视觉特征,旨在提供强大的通用视觉骨干网络,并在各种视觉任务和领域中实现突破性性能。DINOv3在DINOv2的基础上进一步扩展了模型规模和训练数据量,并支持商业许可。
核心功能
- 高分辨率特征生成: 能够产生高质量且分辨率高的图像特征,适用于需要精细视觉信息的任务。
- 通用视觉骨干网络: 提供一个强大的、适用于多种视觉任务的通用视觉骨干模型。
- 自监督学习能力: 利用海量无标注数据进行训练,无需人工标注即可学习强大的视觉表征。
- 跨领域性能优越: 在图像分类、语义分割、目标检测、视频目标跟踪等多种探测任务上超越传统弱监督模型。
- 适应性强: 预训练的DINOv3模型可以通过轻量级适配器在少量标注数据上进行定制,实现更广泛的应用。
- 部署灵活性: 包含蒸馏后的较小模型(如ViT-B、ViT-L)和ConvNeXt变体,便于在不同场景下部署。
技术原理
DINOv3的核心技术原理在于大规模自监督学习(SSL)。它在DINOv2的基础上进行了显著的扩展,模型参数量达到7B,训练数据集规模达到1.7B图像,但相比弱监督方法,所需的计算资源更少。
- 自监督训练: 通过构建无需人工标注的任务来学习图像的内在结构和特征,例如预测图像不同视图之间的关系。
- 视觉Transformer (ViT) 架构: 采用ViT作为其特征提取器,能够有效处理高分辨率图像并捕捉全局依赖关系。
- 模型与数据规模化: 通过将模型尺寸扩大6倍、训练数据量扩大12倍,显著提升了模型性能和泛化能力。
- 冻结骨干网络: 在许多应用中,DINOv3的骨干网络可以保持冻结状态,无需额外微调即可应用于新任务,这得益于其强大的通用特征提取能力。
- 轻量级适配器: 对于特定任务,可以通过训练一个轻量级适配器来微调模型,而非对整个大型模型进行重新训练,从而提高效率。
应用场景
图像分类: 对各种图像进行准确的类别识别。
语义分割: 精确识别图像中每个像素所属的对象类别。
目标检测: 在图像中定位并识别出特定对象。
视频目标跟踪: 在视频序列中持续追踪特定目标。
医学影像分析: 处理和理解医学图像,辅助诊断。
卫星图像分析: 支持对卫星影像进行解析,例如冠层高度估计等。
遥感图像处理: 应用于土地利用、环境监测等领域的遥感数据分析。
安防监控: 进行智能视频监控中的行为识别与异常检测。
自动驾驶: 用于环境感知和目标识别。
任何标注数据稀缺的视觉任务: 由于其强大的自监督学习能力,特别适用于缺乏大量标注数据的领域。
项目官网:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
HuggingFace模型库:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
技术论文:https://ai.meta.com/research/publications/dinov3/
CombatVLA – 淘天3D动作游戏专用VLA模型
CombatVLA 是由淘天集团未来生活实验室团队开发的一种高效视觉-语言-动作(VLA)模型,专为3D动作角色扮演游戏(ARPG)中的战斗任务设计。该模型旨在通过整合视觉感知、语言理解和动作控制,提升AI在复杂游戏环境中的表现。
核心功能
CombatVLA 的核心功能在于对3D ARPG中战斗任务的优化。它能够:
- 战斗理解与推理: 识别敌方位置,并进行动作推理。
- 高效执行: 相比现有基于VLM的游戏智能体,显著提升执行速度。
- 多模态控制: 处理视觉输入,并生成一系列操作指令(包括键盘和鼠标操作)来控制游戏。
- 性能超越: 在战斗理解方面超越了GPT-4o和Qwen2.5-VL等现有模型,并在CUBench基准测试中取得了高分。
技术原理
CombatVLA 基于一个3B参数规模的VLA模型,其技术原理涉及:
- 视觉-语言-动作(VLA)集成: 模型将视觉信息,自然语言指令和游戏内的动作输出进行统一学习。
- 高效推理设计: 专门设计以实现高效推理,大幅提升处理速度。
- 基准测试构建: 建立了名为CUBench的战斗理解基准,通过VQA(视觉问答)格式评估模型在识别敌方位置和动作推理任务中的表现。
- 模型架构: 能够处理视觉输入并生成控制游戏动作的序列。
应用场景
CombatVLA 的主要应用场景集中在:
3D动作角色扮演游戏(ARPG): 尤其适用于其中复杂的战斗任务,可以作为游戏AI或游戏测试工具。
智能体训练: 为在复杂动作游戏环境中训练多模态智能体提供新的见解和方向。
游戏开发: 有助于开发更智能、更具响应性的游戏内NPC或AI对手。
虚拟环境模拟: 可应用于其他需要视觉感知、语言理解和精准操作的虚拟环境。
项目官网:https://combatvla.github.io/
GitHub仓库:https://github.com/ChenVoid/CombatVLA
arXiv技术论文:https://arxiv.org/pdf/2503.09527
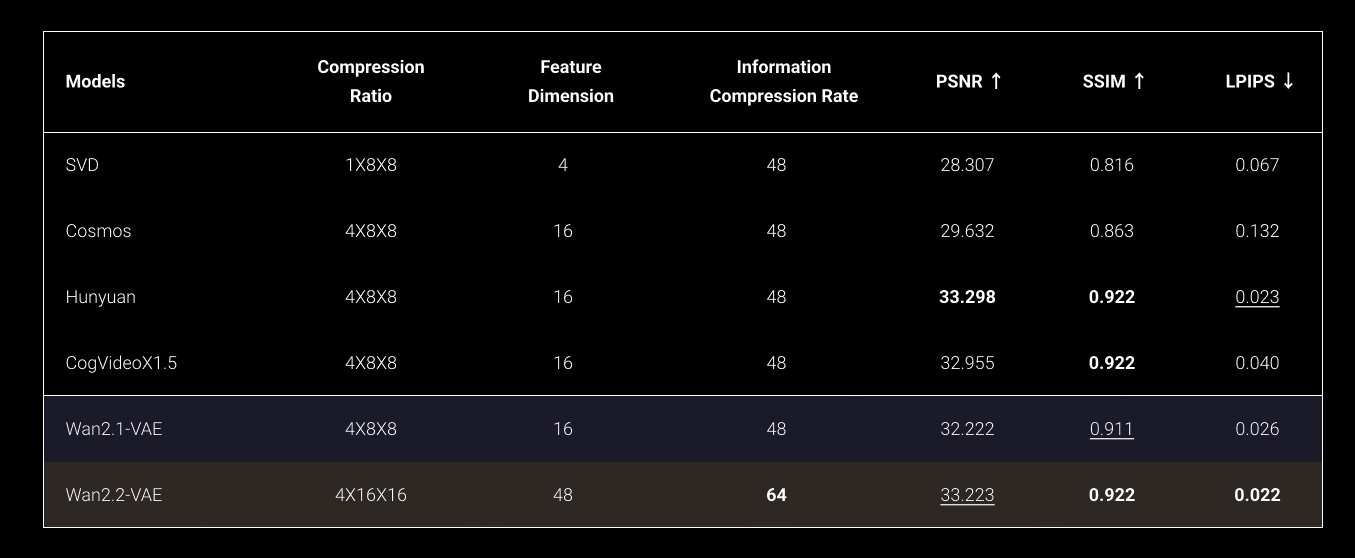
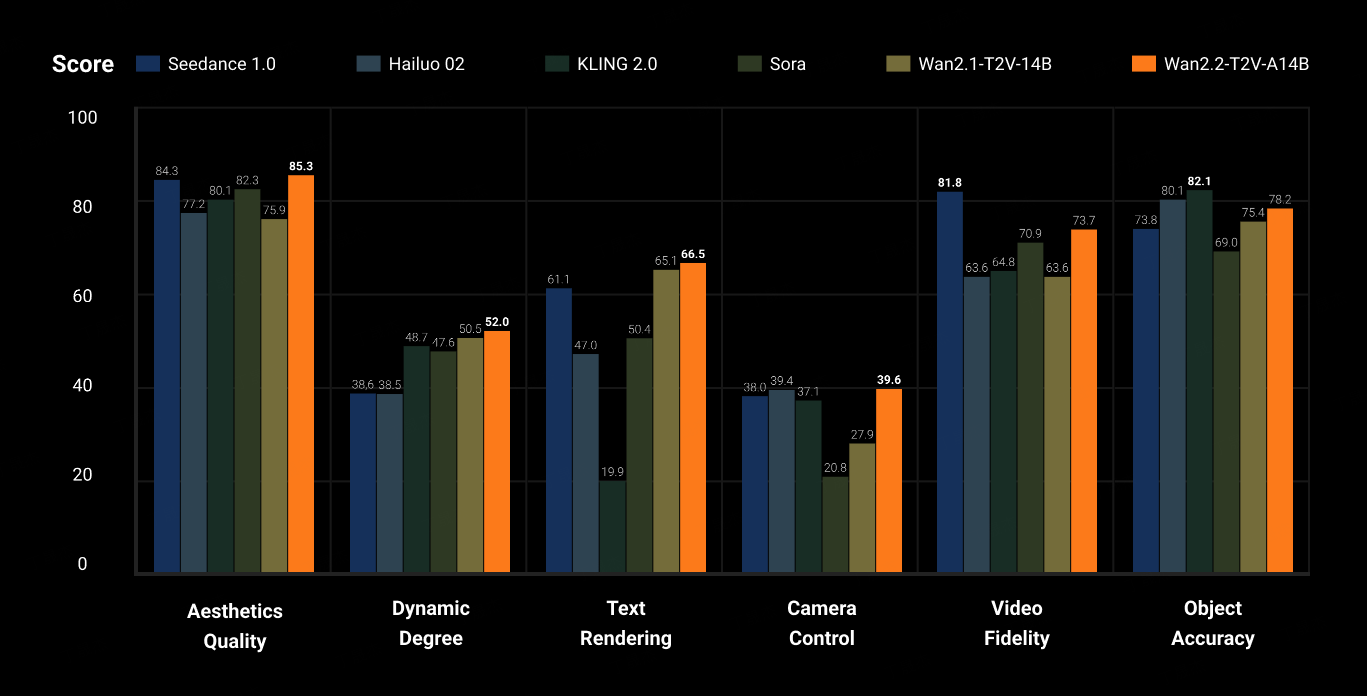
Wan2.2-S2V – 阿里多模态视频生成模型
Wan2.2是由阿里AI团队开发的一款先进的音视频生成模型,尤其以Wan2.2-S2V-14B和Wan2.2-5B模型为代表。它旨在提供高质量、高清晰度的视频生成能力,支持文本到视频(T2V)、图像到视频(I2V)以及音频驱动的电影级视频生成,并通过优化模型架构和数据训练,实现了在消费级GPU上的高效运行。
核心功能
- 多模态视频生成: 能够根据文本描述、图像或音频输入,生成高质量、电影级的视频内容。
- 高分辨率与帧率支持: 支持生成720P分辨率、24帧每秒(fps)的视频输出。
- 复杂运动与美学生成: 通过大量数据训练,显著增强了模型在运动、语义和美学方面的泛化能力,能够生成具有丰富细节、光影和情绪的视频。
- 高效推理: 优化了计算效率,支持在NVIDIA RTX 4090等消费级显卡上快速生成视频。
- 易于集成与部署: 提供推理代码和模型权重,并已集成到ComfyUI、ModelScope Gradio和HuggingFace Gradio等平台。
技术原理
Wan2.2在技术上进行了多项创新。核心模型如Wan2.2-S2V-14B采用了14B参数,而TI2V-5B模型则结合了先进的Wan2.2-VAE,实现了16×16×4的高压缩比,从而在保证生成质量的同时显著提升了效率并降低了计算资源需求。模型在训练阶段使用了比Wan2.1更庞大的数据集(图片和视频数量分别增加65.6%和83.2%),并特别注重对数据进行美学标签(如光照、构图、色调)的标注,使得模型能够学习和生成具有视觉吸引力的视频。此外,它可能采用了类似"专家混合"(Mixture-of-Experts)的路由机制,根据信噪比(SNR)动态切换不同的专家模型来处理视频生成的不同阶段。
- 官网:https://tongyi.aliyun.com/wanxiang/welcome#s2v
- Github:https://github.com/Wan-Video/Wan2.2
- 魔搭社区:https://www.modelscope.cn/models/Wan-AI/Wan2.2-S2V-14B
- HuggingFace:https://huggingface.co/Wan-AI/Wan2.2-S2V-14B
EchoMimicV3 – 蚂蚁多模态数字人视频生成框架
EchoMimicV3 是蚂蚁集团推出的一款高效的多模态、多任务数字人视频生成框架。该框架拥有13亿参数,旨在统一和简化数字人动画生成过程,能够通过音频、图像或两者结合,生成逼真的人物肖像视频。它采用了任务混合和模态混合范式,并结合了新颖的训练与推理策略,使得其生成质量可与参数量大10倍的模型媲美。
核心功能
EchoMimicV3 的核心功能包括:
- 统一的多任务人体动画生成: 能够处理唇形同步、音频驱动全身动画以及从起始帧到结束帧的视频生成等多种人体动画任务。
- 多模态融合能力: 支持结合文本、图像和音频等多种模态条件,以生成更丰富、更具表现力的数字人视频。
- 高效率与高质量: 尽管参数量相对较小(1.3亿),但通过优化设计和训练策略,实现了与大型模型相当的生成质量。
- 音频驱动肖像动画: 能够赋予静态图像生动的语音和表情,生成高度逼真的动态肖像视频。
技术原理
EchoMimicV3 的技术原理基于以下核心设计:
- 统一的多任务范式 (Unified Multi-Task Paradigm): 受MAE(Masked Autoencoders)启发,将不同的人体动画生成任务视为时空局部重建问题,通过仅修改输入端来适应各种生成任务。
- 多模态解耦交叉注意力模块 (Multi-Modal Decoupled Cross-Attention Module): 针对文本、图像和音频等多种模态条件,引入该模块以"分而治之"的方式融合多模态信息,有效处理不同模态间的相互作用与划分。
- SFT+奖励交替训练范式 (SFT+Reward Alternating Training Paradigm): 采用监督微调(SFT)与奖励模型交替训练的策略,通过对齐人类偏好,提升模型性能,使得小参数模型也能达到卓越的生成效果。
应用场景
EchoMimicV3 在数字人生成领域具有广泛的应用前景,包括但不限于:
虚拟主播/数字员工: 用于创建逼真的虚拟形象,在新闻播报、客服、教育培训等领域提供交互服务。
内容创作: 助力视频创作者快速生成高质量的数字人视频内容,如短视频、广告、动画片等。
虚拟人直播: 提供更生动,自然的数字人直播体验,降低真人出镜成本。
个性化营销: 生成定制化的数字人形象,用于产品宣传和品牌推广。
娱乐与游戏: 在虚拟偶像、游戏角色动画等方面提供技术支持,增强用户体验。
项目官网:https://antgroup.github.io/ai/echomimic_v3/
GitHub仓库:https://github.com/antgroup/echomimic_v3
HuggingFace模型库:https://huggingface.co/BadToBest/EchoMimicV3
arXiv技术论文:https://arxiv.org/pdf/2507.03905
SlowFast-LLaVA-1.5 – 苹果推出的多模态长视频理解模型
SlowFast-LLaVA-1.5 是苹果公司推出的一款高效视频大语言模型 (VLLM),专为长视频理解和分析而设计。它整合了 SlowFast 网络架构与 LLaVA 1.5 视觉语言模型,旨在不进行额外训练的情况下,提升模型对视频内容的空间细节和长时间序列上下文的理解能力,从而实现视频问答、视频描述生成等多种任务。
核心功能
- 长视频理解与分析:能够处理和理解长时间跨度的视频内容,捕捉视频中的关键事件和信息。
- 视频问答 (Video QA):基于视频内容回答用户提出的自然语言问题,例如"视频中发生了什么?“或"视频中的物体是什么颜色?"。
- 视频描述生成 (Video Captioning):自动生成对视频内容的详细描述或摘要。
- 多模态交互:结合视频的视觉信息和文本的语言信息进行推理和交互。
- 无需训练的基线性能:在不进行额外微调的情况下,在多项视频理解任务上展现出强大的性能。
技术原理
SlowFast-LLaVA-1.5 的核心在于其创新的 SlowFast 输入设计,将视频输入有效地解耦为两个并行流,以捕捉不同粒度的时空信息:
- 慢速流 (Slow Pathway):以较低帧率处理视频帧,捕获视频中缓慢变化的动作和长时间的上下文信息。这有助于理解视频的整体叙事和语义。
- 快速流 (Fast Pathway):以较高帧率处理视频帧,捕获快速变化的动作和精细的空间细节。这有助于识别视频中的瞬时事件和局部特征。
- 这两个流的特征通过特定的融合机制结合,然后输入到 LLaVA 1.5 视觉语言模型中进行进一步的推理和语言生成。这种双流机制有效地平衡了计算效率和信息捕获的全面性,使其能够高效地处理长视频数据,并从中提取丰富的时空特征。
应用场景
视频内容检索与管理:帮助用户通过自然语言查询快速定位视频中的特定内容或事件。
智能监控与安防:自动识别监控视频中的异常行为或关键事件,提升安全响应效率。
教育与培训:辅助分析教学视频,生成课程摘要或进行交互式问答。
娱乐与媒体:自动生成电影、电视剧或短视频的摘要、字幕或描述,提升内容的可访问性。
智能客服与助手:支持通过视频进行问题诊断或提供操作指导,例如设备故障排查。
GitHub仓库:https://github.com/apple/ml-slowfast-llava
arXiv技术论文:https://arxiv.org/html/2503.18943v1
SpatialLM 1.5 – 群核科技推出的空间语言模型
SpatialLM是由群核科技(Manycore Research)推出的一款强大的空间大语言模型,旨在将大语言模型的能力扩展到三维空间理解。它能够处理三维点云数据,理解自然语言指令,并生成包含空间结构、物体关系和物理参数的空间语言,从而实现对三维场景的结构化理解和重建。
核心功能
- 空间语言理解与生成: 能够解析自然语言指令,并以空间语言的形式输出三维场景中的结构、物体关系及物理参数。
- 三维场景结构化: 将原始三维点云数据转换为高级、结构化的三维场景理解输出,包括室内布局重建。
- 多模态点云处理: 支持处理来自多种来源的密集点云数据,例如单目视频序列、RGBD图像和LiDAR传感器。
- 零样本物体检测: 在无需额外训练的情况下,对三维场景中的物体进行检测和识别。
技术原理
SpatialLM的核心技术原理是将深度学习与三维几何处理相结合,具体包括:
- 3D大语言模型架构: 构建在大型语言模型之上,使其具备理解和生成空间信息的能力。
- 点云编码与特征提取: 利用如Sonata点云编码器等技术,高效地对原始三维点云数据进行编码和特征提取。
- SLAM技术集成: 通过整合同步定位与地图构建(SLAM)技术,例如MASt3R-SLAM,实现从动态视频流等数据中精确重建三维空间布局。
- 结构化表示转换: 将处理后的点云数据转换为易于机器理解和操作的结构化表示,实现对空间语义的高级理解。
应用场景
结构化室内建模: 用于快速、精确地构建和更新室内环境的三维模型。
机器人导航与感知: 为服务机器人、工业机器人等提供精细的空间感知和环境理解能力,实现更智能的自主导航和操作。
三维设计与制造: 作为三维空间生成式AI引擎,辅助建筑设计、产品设计和虚拟原型制造等领域。
增强现实/虚拟现实(AR/VR): 用于构建逼真、可交互的虚拟环境,提升AR/VR应用的沉浸感和实用性。
智能家居与空间管理: 实现对智能家居环境的空间布局理解,优化设备控制和空间利用。
SpatialGen 3D场景生成模型
SpatialGen是由Manycore Research团队开发的一个专注于三维室内场景生成的项目。它旨在通过布局引导的方式,自动化生成高质量的3D室内环境,是Manycore Research在三维空间生成式AI引擎方面的研究成果之一。
核心功能
SpatialGen的核心功能是实现布局引导下的三维室内场景生成。这意味着用户可以通过提供特定的空间布局信息,由模型自动生成符合该布局的完整3D室内场景,极大地简化了3D内容创作的流程。
技术原理
SpatialGen的技术原理基于生成式人工智能,特别是针对三维空间数据的生成。它利用深度学习模型,通过学习大量的室内场景数据,掌握空间布局、物体摆放和材质纹理等复杂关系。该系统可能集成了空间理解(Spatial Understanding)和三维设计(3D Design)的先进算法,通过一个生成式AI引擎来实现从抽象布局到具体3D场景的转化。
应用场景
SpatialGen在多个领域具有广泛的应用潜力:
- 建筑与室内设计: 快速生成多样化的室内设计方案,辅助设计师进行概念验证和可视化。
- 游戏开发: 自动化生成游戏中的室内关卡和场景,提高开发效率。
- 虚拟现实(VR)/增强现实(AR): 为VR/AR应用提供丰富的3D室内环境内容。
- 电影与动画制作: 辅助制作人员快速搭建电影或动画中的室内场景。
- 房地产展示: 为房屋销售或租赁提供交互式的3D室内漫游体验。
SpatialGen的项目地址
- GitHub仓库:https://github.com/manycore-research/SpatialGen
- HuggingFace模型库:https://huggingface.co/manycore-research/SpatialGen-1.0
HunyuanVideo-Foley视频音效生成模型
HunyuanVideo-Foley是由腾讯混元团队开源的一款先进的文本-视频-音频(Text-Video-to-Audio, TV2A)生成系统。该系统旨在根据输入的视频内容和文字描述,自动生成高保真且与视频画面及语义高度匹配的音效,从而为无声视频赋予沉浸式的听觉体验,显著提升内容的吸引力和专业度。
核心功能
- 自动音效生成: 能够基于输入的视频画面和附加的文本描述,智能地为视频生成精确,自然的音效。
- 多模态语义均衡响应: 具备理解视频画面并同时结合文字描述的能力,实现多模态信息的平衡处理,生成更具层次感和复合性的音效,避免单模态信息导致的偏差。
- 高保真音效输出: 生成的音效达到专业级音频保真度,能够精准还原声音的细节和质感,满足专业制作对音质的高要求。
技术原理
HunyuanVideo-Foley的核心技术基于以下几个方面:
- 大规模TV2A数据集构建: 模型训练依赖于一个约10万小时级的高质量文本-视频-音频(TV2A)数据集,通过自动化标注和过滤方式构建,为模型的泛化能力提供了坚实基础。
- 多模态扩散变换器(MMDiT)架构: 采用双流MMDiT架构,通过联合自注意力机制对视频和音频的帧级别对齐关系进行建模,并通过交叉注意力机制有效地注入文本信息,解决了多模态数据融合中的模态竞争问题,实现了视频、音频和文本间的精准对齐。
- 表征对齐(REPA)损失函数: 引入预训练音频特征作为建模过程的语义与声学指导,通过最大化预训练表示与内部表示之间的余弦相似度,显著提升了生成音频的质量和稳定性,并有效抑制了背景噪音和不一致的音效瑕疵。
应用场景
短视频创作: 为短视频内容创作者提供高效的音效生成方案,快速提升视频的感官体验。
电影与广告制作: 在电影、电视剧和广告片的后期制作中,用于自动生成或辅助制作场景化音效,提高制作效率和视听效果。
游戏开发: 为游戏中的角色动作、环境变化和事件触发等提供自动化音效匹配与生成,增强游戏沉浸感。
多媒体内容生产: 广泛应用于各类多媒体内容的制作,如教育、新闻、纪录片等,快速为无声或音效不足的视频添加高质量声音。
项目官网:https://szczesnys.github.io/hunyuanvideo-foley/
GitHub仓库:https://github.com/Tencent-Hunyuan/HunyuanVideo-Foley
HuggingFace模型库:https://huggingface.co/tencent/HunyuanVideo-Foley
OmniHuman-1.5 – 字节数字人动画生成模型
OmniHuman-1.5是字节跳动推出的一款先进的AI模型,旨在从单张图片和语音轨道生成富有表现力、上下文连贯且情绪化的数字人动画。该模型模拟人类的"系统1和系统2"双重认知理论,结合了多模态大语言模型(MLLM)和扩散变换器(Diffusion Transformer),实现了从审慎规划到直觉反应的模拟,极大地提升了数字内容创作的效率和表现力。
核心功能
- 动画生成: 能够从单一图像和语音轨道生成高质量的数字人动画。
- 多角色互动: 支持生成多角色动画,并能实现角色间的复杂互动。
- 情感表现: 生成的数字人动画具有丰富的情感表现力,能根据语音和文本提示做出相应的情感反应。
- 文本细化与动态调整: 支持通过文本提示对动画进行进一步的细化和调整,提升动画的准确性和表现力。
- 动态场景: 能够生成动态背景和场景,使动画更加生动和真实。
技术原理
- 双重系统认知理论(Dual System Cognitive Theory): 模型设计灵感来源于人类的认知过程,模拟了"系统1”(快速、直觉反应)和"系统2"(慢速、深思熟虑)的认知模式,使其能同时处理复杂的逻辑和直观的情感反应。
- 多模态大语言模型(Multimodal Large Language Models, MLLM): 用于处理文本和语音输入,提供高层次的语义指导,理解上下文和情感,从而生成与语音节奏、语调和语义内容一致的动画。
- 扩散变换器(Diffusion Transformer, DiT)架构: 负责生成高质量的动画帧,确保动画的流畅性和视觉效果。它能有效融合多种模态输入,并缓解模态间的冲突。OmniHuman-1.5在MMDiT(Masked Multimodal Diffusion Transformer)架构基础上进行了显著增强。
- 多模态融合: 将图像、语音、文本等多种模态的信息进行深度融合,以生成更丰富、更真实的动画。
- 伪参考帧机制: 通过在最后一帧位置放置用户参考图像,并调整其位置编码,引导模型保持对参考身份的忠诚度,同时避免训练伪影。
应用场景
动画制作: 快速生成高质量角色动画,显著降低制作成本并提升创作效率。
游戏开发: 为游戏角色生成自然、生动的动画,增强游戏的沉浸感和玩家互动体验。
虚拟现实(VR)和增强现实(AR): 创建逼真的虚拟角色和交互式内容,提升用户在VR/AR环境中的体验和趣味性。
社交媒体和内容创作: 快速生成动画内容,适用于短视频和直播平台,提升内容的互动性和吸引力。
数字人及虚拟主播: 用于创建具有情感和认知能力的数字人,应用于客服、教育、娱乐等领域。
项目官网:https://omnihuman-lab.github.io/v1_5/
arXiv技术论文:https://arxiv.org/pdf/2508.19209
Waver 1.0 –字节AI视频生成模型
Waver 1.0是一个下一代的人工智能视频工具,也是一个通用的基础模型,专为统一的图像和视频生成而设计。它利用先进的AI技术,将静态的文字和图像无缝转换为动态的视频内容,旨在提供高质量、高速度和高创造性的AI生成视频解决方案。
核心功能
- 多模态生成: 支持文本到视频 (T2V)、图像到视频 (I2V) 以及文本到图像 (T2I) 的内容生成。
- 视频生成能力: 可直接生成时长5到10秒的720p视频,并可升级至1080p分辨率。
- 灵活性与控制性: 提供灵活的分辨率和宽高比,支持任意视频长度,并易于扩展以实现可控的视频生成。
- 性能优化: 具备更快的渲染时间、增强的视频质量以及更深度的自定义选项。
技术原理
Waver模型基于整流流Transformer架构构建,旨在实现工业级性能。其核心包含两个主要模块:
- 任务统一的DiT (Diffusion Transformer): 负责生成720p分辨率、5到10秒时长的视频。
- 级联精炼器 (Cascade Refiner): 用于将生成的视频从720p分辨率提升至1080p。
- 模型的训练过程注重从低分辨率视频(如192p)学习运动,随后逐步提高分辨率至480p和720p,并采用类似于SD3的流匹配训练设置。在文本到图像生成方面,它利用了
lognorm(0.5, 1)概率密度函数。
应用场景
社交媒体内容创作: 快速生成引人注目的短视频,满足社交平台的需求。
专业内容制作: 适用于需要高质量AI生成视频的创作者和企业,例如营销、教育、媒体等领域。
静态媒体动态化: 将现有文字内容或图片素材转化为视觉吸引力强的视频,提升表达效果。
项目官网:http://www.waver.video/
Github仓库:https://github.com/FoundationVision/Waver
arXiv技术论文:https://arxiv.org/pdf/2508.15761
MAI-Voice-1 – 微软极速语音生成模型
MAI-Voice-1是微软人工智能团队推出的首个内部开发的、具有高度表现力和自然度的语音生成模型。它代表了微软在语音AI领域自主研发的重要进展,旨在提供高效、逼真的语音合成能力。
核心功能
- 高表现力语音生成: 能够生成听起来高度自然且富有表现力的语音。
- 高效音频合成: 可以在单个GPU上不到一秒钟内生成一分钟的音频,显示出极高的运算效率。
- 多场景集成: 已集成到微软的Copilot Daily和播客等产品中。
技术原理
MAI-Voice-1的开发得益于微软对下一代GB200 GPU集群的利用,该集群是专门为训练大型生成模型而优化的定制基础设施。这表明其技术原理可能涉及先进的深度学习架构,如基于Transformer或扩散模型的生成网络,并通过大规模并行计算和优化算法实现了高效的语音合成,从而在保证高质量输出的同时,显著提升了生成速度。
应用场景
智能助手: 用于提升Copilot等智能助手的语音交互体验,使其声音更自然、富有情感。
播客与内容创作: 为播客、有声读物或其他多媒体内容提供高质量的自动语音生成服务。
辅助功能: 为视力受损用户提供更自然、易于理解的文字转语音服务。
开发者工具与实验室: 通过Copilot Labs等平台提供给开发者和研究人员进行探索和创新。
企业应用: 可集成到客服、培训、广播通知等企业级应用中,实现高效的语音信息传递。
MiniCPM-V 4.5 – 面壁端侧多模态模型
MiniCPM-V 4.5是MiniCPM-V系列中最新、功能最强大的模型,总参数量为80亿,由Qwen3-8B和SigLIP2-400M构建。它在视觉-语言能力方面表现卓越,超越了GPT-4o-latest、Gemini 2.0 Pro等专有模型以及Qwen2.5-VL 72B等开源模型,成为30亿参数以下性能最佳的端侧多模态模型。该版本显著提升了性能并引入了高效高刷新率长视频理解、可控的混合快/深度思维等新功能。
核心功能
- 多模态理解能力: 接受图像、视频和文本作为输入,并输出高质量文本,MiniCPM-o版本还支持音频输入和高质量语音输出。
- 高分辨率图像处理: 基于LLaVA-UHD架构,能处理任意宽高比、高达180万像素(如1344x1344)的高分辨率图像,且视觉token使用量比大多数多模态大语言模型(MLLMs)少4倍。
- 混合快/深度思维模式: 提供"快思考"和"深度思考"两种可切换模式,通过混合强化学习方法优化,平衡了日常使用效率和复杂任务处理能力。
- 高效视频理解: 支持高效的高刷新率和长视频理解,视频token压缩率高达96倍。
- 文档解析与OCR: 在OCRBench和OmniDocBench上表现出色,具有领先的OCR识别和PDF文档解析能力。
技术原理
MiniCPM-V 4.5模型基于Qwen3-8B语言模型和SigLIP2-400M视觉模型进行构建。其核心技术原理包括:
- LLaVA-UHD架构: 用于高效处理高分辨率图像,通过减少视觉token数量来优化性能。
- 混合强化学习(Hybrid Fast/Deep Thinking with Multimodal RL): 结合RLPR和RLAIF-V技术,共同优化模型的快思考和深度思考模式,以泛化鲁棒的推理技能。
- RLAIF-V和VisCPM技术: 这些技术被用于进一步提升模型的视觉-语言对齐和推理能力。
- 参数优化: 采用80亿参数的紧凑设计,实现在端侧设备上的高性能部署。
- 高效视频编码: 通过高压缩率(96x)处理视频tokens,实现高效长视频理解。
应用场景
移动端设备与边缘计算: 作为性能最佳的端侧多模态模型,适用于手机、平板等资源受限设备上的AI应用。
智能助理与对话系统: 可用于开发能理解图像、视频和文本输入,并进行智能问答和交互的智能助理。
文档自动化与处理: 凭借其强大的OCR和PDF文档解析能力,可应用于自动化文档录入、信息提取和报告生成等领域。
视频内容分析: 适用于视频监控、短视频内容理解、视频摘要生成等需要高效处理视频流的场景。
多媒体内容创作与理解: 为内容创作者提供基于图像和视频的智能辅助,如图像描述、视频字幕生成等。
GitHub仓库:https://github.com/OpenBMB/MiniCPM-V
HuggingFace模型库:https://huggingface.co/openbmb/MiniCPM-V-4_5
在线体验Demo:http://101.126.42.235:30910/
阶跃发布端到端语音大模型Step-Audio 2 mini
阶跃星辰发布端到端语音大模型 Step - Audio 2 mini,在多个国际基准测试集获 SOTA 成绩。它将语音理解、音频推理与生成统一建模,支持语音原生的 Tool Calling 能力,已上线 GitHub、Hugging Face 等平台。
核心功能
- 多任务处理:在音频理解、语音识别、跨语种翻译、情感与副语言解析、语音对话等任务中表现出色。
- Tool Calling 能力:率先支持语音原生的 Tool Calling,可实现联网搜索等操作。
- 精细理解与回应:能对情绪、语调等副语言和非语音信号精细理解、推理并自然回应。
- 逻辑推理:可将抽象哲学问题转化为具体方法论,引导用户解决问题。
技术原理
真端到端多模态架构:突破传统 ASR + LLM + TTS 三级结构,实现原始音频输入到语音响应输出的直接转换。
CoT 推理结合强化学习:在端到端语音模型中首次引入链式思维推理与强化学习联合优化。
音频知识增强:支持包括 web 检索等外部工具,解决幻觉问题,赋予多场景扩展能力。
GitHub:https://github.com/stepfun-ai/Step-Audio2
Hugging Face:https://huggingface.co/stepfun-ai/Step-Audio-2-mini
ModelScope:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini
GitHub:https://github.com/stepfun-ai/Step-Audio2
Hugging Face:https://huggingface.co/stepfun-ai/Step-Audio-2-mini
ModelScope:https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini
Hunyuan-MT-7B – 腾讯混元翻译模型
腾讯混元-MT-7B(Hunyuan-MT-7B)是腾讯混元团队发布的一款轻量级开源翻译模型。该模型参数量仅为70亿,旨在提供高效、准确的机器翻译服务。尽管体量较小,但其性能据称可与一些闭源大型模型相媲美,致力于推动人工智能翻译的开放研究和应用。
核心功能
- 多语言翻译: 支持33种语言的互译。
- 方言/民汉语言互译: 特别支持5种中国民汉语言/方言的互译。
- 高效翻译: 作为轻量级模型,能在保证翻译质量的同时提供较高的翻译效率。
- 模型组合: 除了基础的Hunyuan-MT-7B翻译模型,还包含一个集成了Hunyuan-MT-Chimera的增强模型,用于提升翻译表现。
技术原理
Hunyuan-MT-7B是一款基于Transformer架构的轻量级翻译模型,拥有70亿参数。该模型通过大规模多语言数据进行训练,以实现跨语言的准确映射。其设计理念强调在模型规模和翻译性能之间取得平衡,使其能够在资源受限的环境下运行。此外,该系列还提供了量化版本(如fp8),进一步优化了模型部署和推理效率。Hunyuan-MT-Chimera作为集成模型,可能采用了模型融合(ensemble)技术,结合多个模型的优势来提升整体翻译质量和鲁棒性。
应用场景
跨境交流与商务: 用于国际商务沟通、邮件往来、文档翻译等场景。
多语种内容创作与本地化: 辅助新闻、出版物、网站、应用程序等内容的快速翻译和本地化。
个人学习与旅游: 提供即时语言翻译支持,便于跨文化交流和学习。
教育领域: 作为语言学习辅助工具,帮助学生理解不同语言的文本。
研究与开发: 作为开源模型,可供研究人员在此基础上进行二次开发和创新,探索更多翻译技术与应用。
Github:https://github.com/Tencent-Hunyuan/Hunyuan-MT/
HuggingFace:https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
HunyuanWorld-Voyager – 腾讯世界模型
腾讯混元团队推出的HunyuanWorld-Voyager(混元Voyager)是业界首个支持原生3D重建的超长漫游世界模型。它是一个新颖的视频扩散框架,能够从单张图片生成用户定义的相机路径,并进一步生成与世界一致的3D点云序列,旨在重新定义AI驱动的空间智能。该模型基于HunyuanWorld 1.0构建,并已进行开源。
核心功能
- 原生3D重建与漫游世界生成: 能够进行超长距离的3D世界重建,并支持用户在生成的3D环境中进行漫游。
- 单图生成视频序列: 从一张静态图片生成与世界一致的、由相机路径控制的3D点云序列或RGB-D序列。
- 沉浸式3D世界创建: 支持从文本或图像条件生成沉浸式、可探索和交互式的3D世界。
- 物理渲染材质生成: 结合了PBR(Physically-Based Rendering)材质合成,能够生成具有电影级光照交互效果的逼真材质。
技术原理
HunyuanWorld-Voyager采用创新的视频扩散框架,其技术核心包括:
- 视频扩散模型: 利用扩散模型生成连贯的视频序列,实现图像到视频的转换。
- 原生3D重建: 不同于传统的2D生成再推断3D的方法,该模型实现了原生3D重建能力。
- 世界缓存方案与自回归视频采样: 引入高效的世界缓存方案和自回归视频采样方法,以支持世界重建和无限世界生成。
- 全景图生成与分层3D重建: 基于HunyuanWorld 1.0,通过全景图像生成、语义分层和分层3D重建等技术,实现高质量的360°场景级3D世界生成。
- 物理渲染(PBR)纹理合成: 采用物理渲染管线,通过物理驱动的材质模拟,生成具有逼真光照交互效果的纹理。
应用场景
虚拟现实(VR)与游戏开发: 用于快速生成沉浸式、可探索的虚拟场景和游戏世界。
电影与动画制作: 提供高效的3D资产创建和场景生成能力,加速影视内容生产流程。
数字孪生与空间智能: 在数字孪生、智能城市规划等领域,通过原生3D重建提供高精度的空间数据和模拟环境。
AI驱动的3D内容创作: 赋能创作者通过AI技术,以前所未有的效率和质量创建3D模型和世界。
项目官网:https://3d-models.hunyuan.tencent.com/world/
Github仓库:https://github.com/Tencent-Hunyuan/HunyuanWorld-Voyager
Hugging Face模型库:https://huggingface.co/tencent/HunyuanWorld-Voyager
技术报告:https://3d-models.hunyuan.tencent.com/voyager/voyager_en/assets/HYWorld_Voyager.pdf
AudioStory – 腾讯音频生成模型
AudioStory是由腾讯ARC实验室开发的一项音频生成技术,旨在根据自然语言描述生成高质量的长篇叙事音频。它通过采用"分而治之"的策略,将复杂的叙事请求分解为有序的子任务,从而实现对长文本的有效处理和音频生成。该技术结合了大型语言模型(LLMs)的能力,以实现更优异的指令遵循能力和音频保真度。
核心功能
- 长篇叙事音频生成: 能够根据文本描述,生成连贯且具有叙事感的长篇音频内容。
- 自然语言描述到音频转换: 将用户输入的自然语言文本,直接转化为对应的音频故事。
- 分而治之策略: 将复杂的生成任务拆解成多个可管理的子任务,优化生成流程。
- 高音质与高保真度: 专注于生成高质量、高保真度的音频输出。
- 指令遵循能力: 能够更好地理解和遵循用户的文本指令,生成符合预期的音频。
技术原理
AudioStory的核心技术原理在于结合了大型语言模型(LLMs)的强大文本理解和生成能力与音频合成技术。它采用一种"分而治之"(Divide and Conquer)的策略,具体可能包括:
- 叙事分解: 将用户提供的长篇叙事文本,通过LLM进行语义分析和结构化分解,划分为多个逻辑上连续的短句或段落。
- 角色/情境感知合成: 对于分解后的每个子任务,LLM可能进一步推断出相应的情绪、语调、角色对话等信息。
- 多模态融合: 将文本信息(包括语义、情感、角色等)转化为音频合成模型可理解的参数,如音高、语速、音色等。
- 序列生成与衔接: 通过先进的深度学习模型(如Transformer架构的变体),逐段生成音频,并确保不同段落之间的自然流畅衔接。
- 音素到波形合成: 利用语音合成技术,将生成的声音特征转换为最终的音频波形。
应用场景
有声读物制作: 快速将小说、故事、新闻文章等文本内容转化为高质量的有声读物。
播客内容生成: 自动化生成播客节目的旁白、故事叙述或特定主题的音频内容。
教育与学习: 制作教学材料、历史故事、科学知识的音频版本,方便学生听觉学习。
游戏与动漫配音: 为游戏角色、动画片、虚拟人物提供快速、定制化的配音。
广告与宣传: 自动生成商品介绍、品牌故事等宣传音频。
无障碍辅助: 为视障人士提供文本转语音的辅助工具,提升信息获取的便利性。
Github仓库:https://github.com/TencentARC/AudioStory
论文地址:https://arxiv.org/pdf/2508.20088
USO – 字节内容与风格解耦与重组统一框架
USO(Unified Style and Subject-Driven Generation via Disentangled and Reward Learning)是由字节跳动智能创作实验室开发并开源的统一风格与主体驱动生成模型。该项目旨在解决传统上将风格驱动和主体驱动生成视为独立任务的局限性,通过一个统一的框架实现二者的融合,能够自由地将任意主体与任意风格结合,生成高质量的图像内容。
核心功能
- 统一图像生成: 能够在一个框架内同时进行风格驱动和主体驱动的图像生成。
- 高保真度输出: 确保生成图像在主体一致性、身份保持以及风格保真度方面达到领先水平。
- 自然人像生成: 特别优化生成自然、无"塑料感"的人像。
- 灵活组合能力: 允许用户自由组合不同的主体和风格,以适应多样化的创作需求。
- 性能评估基准: 发布了USO-Bench,作为首个联合评估风格相似性和主体保真度的开放基准。
技术原理
USO的核心技术在于其解耦与奖励学习(Disentangled and Reward Learning)机制。它通过精巧的算法设计,实现"内容"和"风格"的有效解耦和重组,从而克服了传统方法中风格和主体生成之间的内在矛盾。该模型构建在一个统一的生成框架之上,利用深度生成模型(如基于FLUX.1-dev的模型)进行图像合成。此外,它通过引入奖励学习进一步提升模型性能,确保生成结果的自然度和一致性。项目还进行了GPU内存优化,使其在消费级GPU(峰值显存约16GB)上也可运行。
应用场景
个性化图像定制: 用户可以根据个人喜好或特定需求,生成具有特定风格的自定义人像或场景图像。
数字艺术与创作: 赋能艺术家和设计师进行创新性的数字内容创作,探索不同风格与主题的结合。
虚拟形象生成: 用于创建逼真且风格多变的虚拟人物或数字分身。
娱乐与媒体: 在游戏、影视制作、广告等领域生成高质量的视觉内容。
学术研究: 作为开源项目,为计算机视觉和机器学习领域的研究人员提供了一个先进的基线模型和评估工具。
项目官网:https://bytedance.github.io/USO/
Github仓库:https://github.com/bytedance/USO
arXiv技术论文:https://arxiv.org/pdf/2508.18966
InfinityHuman – 字节AI数字人
InfinityHuman 是一个专注于生成长期、高质量、音频驱动数字人动画的统一框架。它能够根据输入的音频生成具有高分辨率视觉一致性、生动手部和身体动作的数字人视频,特别适用于长视频内容的生成。
核心功能
- 长期音频驱动动画生成: 能够依据音频输入,生成长时间序列的数字人动画,保持视觉和动作的连贯性。
- 高分辨率视觉一致性: 在长时间动画中,保持数字人外观、纹理等视觉细节的高质量和稳定性。
- 逼真手部与身体动作: 生成的数字人动画不仅包含面部表情,还能同步生成逼真的手部和身体动作。
- 音频-动作同步: 实现精确的音频与数字人嘴型、表情、肢体动作的同步,提高真实感。
- 商用级应用潜力: 该框架旨在满足商业应用场景对高质量、长时程数字人内容的需求。
技术原理
InfinityHuman 采用了一种**粗到细(coarse-to-fine)**的生成框架。其核心技术原理包括:
- 音频同步表示生成: 首先,系统从输入的音频中提取特征,并生成与音频严格同步的初步动作表示。
- 渐进式精细化处理: 在生成粗略的音频同步表示后,模型会逐步对其进行精细化处理,包括姿态、表情、手部动作等细节。
- 统一框架设计: 整个系统被设计为一个统一的端到端框架,能够整合音频处理、动作生成和视频渲染等多个模块。
- 长时程一致性保障: 可能引入了时间注意力机制、记忆网络或循环结构来维持长时间跨度内的角色身份、外观和动作的连贯性。
应用场景
虚拟主播与数字人代言: 用于新闻播报、直播,品牌宣传等需要长期稳定输出的场景。
在线教育与培训: 制作虚拟教师或讲师的授课视频,提升互动性和吸引力。
影视动画与游戏制作: 辅助角色动画的快速生成,尤其是在对话和表演驱动的场景中。
个性化内容创作: 用户可以根据自己的音频输入,快速生成定制化的数字人视频内容。
商业演示与客服: 创建更具吸引力和交互性的数字人客服或产品演示。
项目官网:https://infinityhuman.github.io/
arXiv技术论文:https://arxiv.org/pdf/2508.20210
Super Agent Party – 开源3D AI桌面伴侣
Super Agent Party 是一款开源的3D AI桌面伴侣软件,集成了桌宠、智能助手、知识库和机器人控制等多种功能。它旨在为用户提供一个高度可定制和互动的AI伴侣体验,支持通过Docker或源码快速部署到Windows等操作系统,并实现全渠道一键部署。
核心功能
- 多功能集成: 将虚拟桌面宠物、智能问答、知识管理、以及外部机器人控制等多种AI能力整合于一体。
- 代码执行与数据处理: 内置代码执行工具,支持云端和本地解决方案;具备文件/图片链接查看能力,使大模型能检索并理解URL指向的信息。
- 增强型智能体能力: 强化深度研究持久性,支持自定义HTTP代理工具,并更新了内存模块,提升AI的持续学习和交互能力。
- 模型与主题扩展: 提供新主题选择,并扩展了文本到图像模型的支持。
- 接口标准化: 提供兼容OpenAI API的接口和MCP(Model-Context-Protocol)协议支持,便于与外部系统集成和二次开发。
技术原理
Super Agent Party 基于开源架构构建,利用大型模型(LLM)进行智能处理,并通过集成多种工具链实现功能扩展。其核心技术原理包括:
- 多模态交互: 支持3D模型渲染和虚拟形象(VRM)集成,实现视觉交互。
- Agent技术: 运用Agent范式,赋予AI自主规划、执行任务的能力,如通过代码执行工具进行复杂操作。
- 知识图谱与记忆机制: 具备知识库管理和深度研究持久性,暗示采用高效的知识表示和记忆管理技术。
- API与协议集成: 通过与OpenAI API兼容的接口和MCP协议,实现AI能力的标准化输出和跨平台互操作。
- 容器化部署: 支持Docker部署,确保环境隔离、快速部署和跨平台兼容性。
应用场景
个人桌面助手: 作为虚拟桌面伴侣,提供日常问答、信息查询和个性化互动。
智能客服与教育: 结合知识库功能,可应用于智能客服、在线教育辅导等场景。
社交媒体互动: 可部署为微信/QQ官方机器人或Bilibili直播互动伴侣,增强用户参与度。
虚拟现实/游戏: 作为VRM虚拟桌面宠物,为虚拟世界和游戏提供智能NPC或伴侣。
开发与集成: 为开发者提供标准化API,便于将AI能力集成到各类应用和系统中,实现快速原型开发和业务创新。
GitHub仓库:https://github.com/heshengtao/super-agent-party
叠叠社 – AI虚拟陪伴应用
内容涵盖了人工智能聊天机器人(AI Chatbots)的技术定义、核心功能及构建方法,以及与"二次元"文化相关的数字平台和线下沉浸式体验。前者侧重于通过AI算法实现自动化对话和用户交互,后者则包括一款名为"叠叠社"的客户端应用和日本的"二次元之森"(Nijigen no Mori)主题公园,这些都体现了技术在不同领域中的应用与发展。
核心功能
- AI Chatbots: 实现自动化对话、理解用户意图(如自然语言处理和理解)、提供客户服务与信息查询、通过机器学习优化交互,并能与机器人流程自动化(RPA)结合执行任务。
- 叠叠社: 提供安卓和Windows客户端下载,具备内容搜索、夜间模式、信息发布、消息互动、图片浏览、兑换码、每日打卡等用户管理及互动功能。
- 二次元之森 (Nijigen no Mori): 打造以动漫IP为主题的沉浸式游乐体验,如火影忍者、哥斯拉、蜡笔小新、勇者斗恶龙等,融合动画、技术与自然景观,提供游乐设施及多媒体互动。
技术原理
- 人工智能聊天机器人: 核心技术包括**自然语言处理(NLP)和自然语言理解(NLU)以解析用户输入;利用机器学习(ML)和深度学习(DL)**算法优化对话模型并实现自我学习。
- 叠叠社: 作为客户端应用,其技术原理涉及客户端-服务器架构,用于数据传输和管理;数据库管理系统支持用户数据和内容存储。
- 二次元之森: 主要运用多媒体技术(如光影投射、音效设计)和沉浸式互动装置,结合动漫IP内容制作与主题公园规划设计。
应用场景
人工智能聊天机器人: 广泛应用于客户服务、技术支持,信息咨询、业务自动化(如预订、销售)、教育辅导及企业内部沟通等领域。
叠叠社: 适用于二次元爱好者社区、游戏辅助工具、内容分享与管理、社交互动以及个人化信息获取等场景。
二次元之森: 作为旅游景点,其主要应用场景是休闲娱乐、文化体验、家庭出游、动漫粉丝朝圣以及地域文化推广。
OneCAT – 美团联多模态模型
OneCAT是由美团与上海交通大学联合推出的一种新型统一多模态模型。该模型采用纯解码器架构,旨在无缝集成多模态理解、文本到图像生成及图像编辑等功能,通过创新的技术实现了高效的多模态处理和卓越的性能表现。
核心功能
OneCAT的核心功能包括:
- 多模态理解: 能够高效处理和理解图像与文本的综合内容。
- 文本到图像生成: 根据文本描述生成高质量的图像内容。
- 图像编辑: 提供对图像进行修复、风格转换、特效添加等编辑能力。
技术原理
OneCAT在技术上采用了多项创新:
- 纯解码器架构: 摒弃了传统多模态模型对外部视觉编码器和分词器的依赖,简化了模型结构。
- 模态特定专家混合(MoE)结构: 通过针对不同模态的专家混合机制,实现了高效的多模态信息处理。
- 多尺度自回归机制: 支持高分辨率图像的输入和输出处理。
- 尺度感知适配器与多模态多功能注意力机制: 进一步增强了模型的视觉生成能力和跨模态对齐能力。
- 模型变体: 存在OneCAT-1.5B(基于Qwen2.5-1.5B-instruct)和OneCAT-3B(基于Qwen2.5-3B-instruct)等不同参数规模的版本。
应用场景
OneCAT的广泛应用场景包括:
智能客服与内容审核: 理解用户图文信息并提供回复,自动识别和筛选违规内容。
创意设计与数字内容创作: 为设计师和创作者提供创意灵感,快速生成广告、影视、游戏等领域所需的图像素材。
广告设计与营销: 根据广告文案快速生成视觉素材,实现个性化广告内容。
影视后期制作: 用于图像修复、风格转换、特效添加等任务,提升制作效率。
教育与学习: 生成与教学内容相关的图像,辅助学生理解和记忆知识。
项目官网:https://onecat-ai.github.io/
Github仓库:https://github.com/onecat-ai/onecat
HuggingFace模型库:https://huggingface.co/onecat-ai/OneCAT-3B
arXiv技术论文:https://arxiv.org/pdf/2509.03498
rStar2-Agent – 微软
rStar2-Agent是微软研究院推出的一款140亿参数的数学推理模型,通过智能体强化学习(Agentic Reinforcement Learning)进行训练,在数学推理任务上达到了前沿水平,甚至超越了如DeepSeek-R1(6710亿参数)等更大的模型。它不仅具备强大的数学问题解决能力,还展现出高级认知行为,如在使用工具前的深思熟虑以及根据代码执行反馈进行自我纠正和迭代。rStar-Math是微软为提升AI数学推理能力而设计的开源框架,旨在使小型语言模型(SLMs)也能实现与大型模型相当甚至超越的数学推理能力,重点解决高质量数据集缺乏和奖励模型构建复杂等挑战。
核心功能
- 高级数学推理: 能够解决复杂的数学问题,在AIME等竞赛中表现出色,超越现有领先模型。
- 智能体式工具使用: 具备在使用Python编程工具前进行审慎思考,并根据执行反馈自主探索、验证和完善中间步骤的能力。
- 高效训练与推理: 通过创新的智能体强化学习算法(如GRPO-RoC)和高效的训练方法,使得较小规模的模型也能达到顶尖性能,显著提升推理效率。
- 多阶段强化学习: 从非推理SFT(Supervised Fine-Tuning)开始,逐步通过多阶段RL训练,以最小的计算成本获得高级认知能力。
- 泛化能力: 除数学领域外,rStar2-Agent-14B还展示了在对齐(alignment)、科学推理和智能体工具使用任务上的强大泛化能力。
技术原理
rStar2-Agent的核心技术原理包括:
- 智能体强化学习 (Agentic Reinforcement Learning, RL): 采用GRPO-RoC(Generalized Reinforcement Learning with Policy Optimization - Resample on Correct)等创新算法,在答案导向的奖励机制下进行高效的智能体训练。
- Resample on Correct (RoC) 策略: 一种有效的策略,通过过采样更大批次的轨迹,然后对高质量的正面轨迹进行过滤和下采样,同时均匀下采样负面轨迹,以优化强化学习过程。
- 高效可靠的代码执行环境: 构建高吞吐量、隔离的代码执行环境,确保模型在使用外部工具时的稳定性和准确性。
- 思维链(Chain-of-Thought, CoT)超越: 不同于传统长CoT过程,rStar2-Agent通过其智能体行为和反馈循环,实现更深层次的认知行为。
应用场景
教育与学习辅助: 作为高级智能辅导系统,帮助学生解决复杂的数学问题,并提供解题思路和步骤。
科学研究与工程: 加速科学发现过程,辅助工程师进行复杂计算和问题求解。
智能体系统开发: 为需要高级推理能力和工具使用能力的AI智能体提供核心技术支持。
自动化内容生成与验证: 在需要严谨逻辑推理的内容生成和验证中发挥作用。
金融建模与分析: 应用于复杂的金融模型构建和数据分析,提高预测准确性。
GitHub仓库:https://github.com/microsoft/rStar
arXiv技术论文:https://www.arxiv.org/pdf/2508.20722
MiniCPM 4.1 –混合思考模型
MiniCPM和MiniCPM4.1系列是OpenBMB团队开发的一系列极致高效的端侧大语言模型(LLMs),专注于在边缘设备上实现高性能。它们通过在模型架构、学习算法、训练数据和推理系统四个维度进行系统性创新和优化,旨在提供卓越的效率提升和强大的功能,使其成为本地部署和AI PC等场景的理想选择。
核心功能
- 极致高效的端侧推理能力: 专为在资源受限的端侧设备上高效运行而设计,实现高生成速度。
- 强大的语言理解与指令遵循: 具备优秀的自然语言处理能力,能够准确理解用户意图并执行复杂指令。
- 领先的多模态视觉能力(MiniCPM-V系列): MiniCPM-V 4.0等版本在低参数量下展现出卓越的图像和视频理解能力。
- 深度硬件适配: 全面支持Intel Core Ultra系列处理器,并与OpenVINO™等推理框架深度融合。
- 隐私安全保障: 采用本地部署方式,所有数据处理均在本地完成,有效避免数据上传至云端带来的隐私风险。
技术原理
四维优化策略: 模型的效率提升基于对模型架构、学习算法、高质量训练数据和高效推理系统的综合考量与创新。
硬件协同优化: 通过与Intel CPU、GPU和NPU架构的深度适配,结合OpenVINO™工具包进行模型量化和运行时优化。
推测解码(Speculative Decoding): 采用此技术以加速模型推理速度,提高吞吐量。
MLA结构优化: 在特定版本中,通过对多层注意力(MLA)结构的优化,显著提升吞吐量。
无限长文本支持: 通过LLMxMapReduce等技术,理论上支持处理无限长文本输入。
Github仓库:https://github.com/openbmb/minicpm
HuggingFace模型库:https://huggingface.co/openbmb/MiniCPM4.1-8B
混元图像2.1 – 腾讯开源的文生图模型
腾讯混元(Hunyuan)系列是腾讯开发的一系列先进AI生成模型,专注于图像、3D模型和视频内容的创作。其中,混元大模型Hunyuan Image 2.1作为核心图像生成模型,以其毫秒级响应速度和卓越的生成质量,为用户提供了前所未有的实时交互式AI创作体验。
核心功能
- 实时图像生成与编辑:支持毫秒级响应速度的文本到图像生成,以及在实时画板上进行多图像融合和自由创作。
- 高保真3D资产生成:能够将图像或文本输入转化为高分辨率、带有PBR(基于物理渲染)材质的3D模型。
- 图像到视频转换(I2V):将静态图像无缝转换为动态视频内容,提供高达720p分辨率和长达5秒的高质量视频输出。
- 文生视频(T2V):基于文本描述直接生成高质量视频,并能实现流畅的场景过渡和专业的特效。
技术原理
混元系列模型融合了多项前沿AI技术:
扩散模型(Diffusion Architecture):图像和视频生成的核心,通过逐步去噪生成高质量内容。
超高压缩图像编码器(Ultra-high Compression Image Encoders):实现高效的数据处理和毫秒级响应速度的关键。
多模态大语言模型(Multimodal Large Language Models):用于理解和处理跨模态的复杂指令。
全尺度多维强化学习后训练(Full-scale Multi-dimensional Reinforcement Learning Post-training):优化模型性能。
对抗蒸馏(Adversarial Distillation):提高模型效率和生成效率。
项目官网:https://hunyuan.tencent.com/image
GitHub仓库:https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
HuggingFace模型库:https://huggingface.co/tencent/HunyuanImage-2.1
SpikingBrain-1.0 – 中国科学院推出的类脑脉冲大模型
SpikingBrain-1.0(瞬悉1.0)是中国科学院自动化研究所推出的类脑脉冲大模型系列,其灵感来源于生物大脑,并采用脉冲神经网络(SNN)来模拟生物神经元的工作方式。该模型旨在突破传统Transformer架构在处理长序列和能耗方面的限制,通过新型非Transformer架构实现高效能和低能耗的大规模语言模型。
核心功能
- 模拟生物神经元行为: 采用脉冲神经网络,模拟生物大脑中神经元的脉冲发放机制。
- 长文本处理能力: 针对长上下文场景进行优化,具备处理超长文本的能力。
- 高效能低能耗: 相较于传统基于Transformer的模型,显著降低计算能耗。
- 无Transformer架构: 采用纯线性复杂度的层间混合架构,突破了Transformer架构的固有局限性。
技术原理
SpikingBrain系列模型的核心在于其独特的脉冲神经网络(Spiking Neural Network, SNN)架构,区别于传统的ANN(Artificial Neural Network)。
脉冲编码与传播: 信息以离散的脉冲信号(spike)形式进行编码和传输。
事件驱动计算: SNN是事件驱动的,只有当神经元接收到足够的脉冲并达到阈值时才会发放脉冲。
非Transformer架构: 模型摒弃了Transformer中自注意力机制的高计算复杂度,转而采用新型的非Transformer架构。
生物启发学习规则: 结合了生物学中突触可塑性等学习规则。
GitHub仓库:https://github.com/BICLab/SpikingBrain-7B
arXiv技术论文:https://arxiv.org/pdf/2509.05276
SRPO – 腾讯混元推出的文生图模型
SRPO(Semantic Relative Preference Optimization)是腾讯混元团队推出的一种先进的文本到图像生成模型。它在现有的Flux模型基础上,通过引入语义相对偏好优化机制,显著提升了生成图像的质量和真实感。
核心功能
- 高质量文本到图像生成:能够根据文本描述生成视觉上更具真实感和更高质量的图像。
- 在线奖励调整:将奖励信号设计为文本条件信号,支持奖励的在线动态调整。
- 优化图像真实感:相比基准模型FLUX,SRPO在生成图像的真实感指标上有大幅提升。
技术原理
SRPO的核心在于其语义相对偏好优化机制。它是在FLUX.1-dev模型基础上构建的在线强化学习版本。
- 奖励信号文本条件化:创新性地将奖励信号与文本条件相结合。
- 奖励模型分支设计:其奖励模型在评分前引入了"惩罚"和"奖励"两个分支。
- 项目官网:https://tencent.github.io/srpo-project-page/
- GitHub仓库:https://github.com/Tencent-Hunyuan/SRPO
- HuggingFace模型库:https://huggingface.co/tencent/SRPO
- arXiv技术论文:https://arxiv.org/pdf/2509.06942v2
Stand-In – 腾讯微信推出的视频生成框架
Stand-In是由腾讯微信视觉团队推出的一种轻量级、即插即用的视频生成框架,专注于实现身份保持的视频生成。该框架通过仅训练1%的基础模型参数,即可生成高保真度、身份一致性强的视频,显著降低了训练成本和部署难度。
核心功能
- 身份保持视频生成: 能够基于一张参考图像,生成具有高度面部相似性和自然度的视频内容。
- 轻量级与即插即用: 仅需微调少量参数即可应用于现有视频生成模型。
- 高保真度: 生成的视频在视觉质量上表现出色。
- 高效训练: 通过引入条件图像分支,避免了显式的面部特征提取器。
技术原理
Stand-In的核心技术原理在于其创新的身份注入机制。它通过引入一个条件图像分支到预训练的视频生成模型中。这个分支将条件图像直接映射到与视频相同的潜在空间。
- 项目官网:https://www.stand-in.tech/
- GitHub仓库:https://github.com/WeChatCV/Stand-In
- HuggingFace模型库:https://huggingface.co/BowenXue/Stand-In
- arXiv技术论文:https://arxiv.org/pdf/2508.07901
HuMo – 清华联合字节推出的多模态视频生成框架
HuMo(Human-Centric Video Generation via Collaborative Multi-Modal Conditioning)是字节跳动研究院开发的一种以人为中心的视频生成统一框架。该框架旨在解决多模态控制中的挑战,通过两阶段训练范式以及创新策略,实现对视频中人物主体的高度保留和音视频同步。
核心功能
- 多模态条件视频生成:能够结合文本描述、图像参考和音频输入来生成视频。
- 主体保存:在视频生成过程中,有效保持人物主体的身份、外观和姿态一致性。
- 音视频同步:实现生成视频中人物的口型、动作与输入音频的精确同步。
- 高可控性:允许用户对生成的视频内容进行精细化控制。
技术原理
HuMo的核心技术原理在于其协作多模态条件机制和两阶段训练范式。
- 多模态融合:模型通过深度学习架构有效地整合来自文本提示、图像参考和音频信号的异构信息。
- 扩散模型 (Diffusion Model):作为生成模型的主体。
- 两阶段训练:第一阶段可能侧重于学习基础的视频生成能力,第二阶段进一步优化主体保持和音视频同步。
- 时间自适应分类器自由引导:使得引导权重能根据去噪过程的不同阶段进行动态调整。
- 项目官网:https://phantom-video.github.io/HuMo/
- HuggingFace模型库:https://huggingface.co/bytedance-research/HuMo
- arXiv技术论文:https://arxiv.org/pdf/2509.08519
ZipVoice – 小米推出的零样本语音合成模型
ZipVoice 是一系列基于流匹配(Flow Matching)的快速、高质量零样本文本到语音(TTS)模型。它旨在解决现有大型零样本 TTS 模型参数庞大、推理速度慢的问题,通过紧凑的模型尺寸和快速的推理速度提供卓越的语音克隆、可懂度和自然度。
核心功能
- 零样本语音合成: 能够根据少量提示音频,合成具有特定音色的语音。
- 高品质语音克隆: 在说话人相似度、可懂度和自然度方面表现出色。
- 快速推理: 模型参数量小(仅约 123M),实现高效、快速的语音生成。
- 多语言支持: 同时支持中文和英文的语音合成。
技术原理
ZipVoice 的核心技术是基于 流匹配(Flow Matching) 范式。
- Zipformer-based 解码器和编码器: 采用 Zipformer 架构构建解码器和编码器。
- 流蒸馏(Flow Distillation): 通过流蒸馏技术实现模型优化。
- 非自回归(Non-Autoregressive)结构: 显著提高了推理效率。
- GitHub仓库:https://github.com/k2-fsa/ZipVoice
- HuggingFace模型库:https://huggingface.co/k2-fsa/ZipVoice
- arXiv技术论文:https://arxiv.org/pdf/2506.13053
Mini-o3 – 字节联合港大推出的视觉推理模型
Mini-o3是由字节跳动和香港大学联合推出的开源模型,专注于解决复杂的视觉搜索问题。它具备强大的"图像思考"能力,能够生成类似于OpenAI o3的多轮代理式轨迹,旨在通过扩展推理模式和交互轮次来增强视觉-语言模型(VLMs)在处理挑战性视觉任务时的性能。
核心功能
- 复杂视觉搜索: 精准处理需要深度视觉理解和多步骤分析的搜索任务。
- 深度多轮推理: 能够执行复杂且连续的推理过程,而非简单的单步识别。
- 代理式轨迹生成: 模拟智能代理的决策路径,生成一系列连贯的动作或思考步骤。
技术原理
Mini-o3的技术核心在于其对视觉-语言模型(VLMs)的强化,通过强化学习(Reinforcement Learning)机制进行训练。模型集成并运用基于图像的工具来分解和解决复杂的视觉问题。
- 项目官网:https://mini-o3.github.io/
- GitHub仓库:https://github.com/Mini-o3/Mini-o3
- HuggingFace模型库:https://huggingface.co/Mini-o3/models
- arXiv技术论文:https://arxiv.org/pdf/2509.07969
LLaSO – 逻辑智能开语音模型
LLaSO(Large Language and Speech Model)是一个由北京深度逻辑智能科技有限公司、智谱AI和清华大学共同推出的全球首个完全开源的大型语音语言模型。
核心功能
- 端到端语音对话: 提供从语音输入到语音输出的完整对话能力。
- 多语言支持: 支持中文和英文的语音及文本处理。
- 开源框架: 开放代码、数据集和预训练模型。
技术原理
LLaSO模型结合了大型语言模型(如Glm-4-9B-Base)与语音处理技术,构建了一个统一的语音语言模型架构。
- GitHub仓库:https://github.com/EIT-NLP/LLaSO
- HuggingFace模型库:https://huggingface.co/papers/2508.15418
- arXiv技术论文:https://arxiv.org/pdf/2508.15418v1
Qwen3-Omni – 全模态大模型
Qwen3-Omni(通义千问3-Omni)是阿里云通义团队推出的业界首个原生端到端全模态AI模型。它旨在无缝处理和统一文本、图像、音频和视频等多种模态数据,通过单一模型实现多模态信息的深度理解与生成。
核心功能
- 端到端全模态理解与生成:能够原生理解并生成文本、图像、音频和视频内容。
- 多语言支持:支持包括中文和英文在内的多语言文本处理。
- 高级视觉处理:具备图像编辑、生成、语义理解及复杂图表数据解读能力。
- 音频视频分析:能够对音频内容进行深度理解,并支持音视频数据的分析处理。
技术原理
Qwen3-Omni基于大型语言模型(LLM)架构,其技术原理的突破点在于实现了"原生端到端"的全模态融合。
统一表征空间:可能通过设计统一的嵌入空间将不同模态的原始数据映射到同一个语义空间中。
共享骨干网络:采用一个共享的Transformer架构作为核心骨干网络。
项目官网:https://qwen.ai/blog?id=65f766fc2dcba7905c1cb69cc4cab90e94126bf4
GitHub仓库:https://github.com/QwenLM/Qwen3-Omni
HuggingFace模型库:https://huggingface.co/collections/Qwen/qwen3-omni-68d100a86cd0906843ceccbe
技术论文:https://github.com/QwenLM/Qwen3-Omni/blob/main/assets/Qwen3_Omni.pdf
Qwen3-TTS-Flash
Qwen3-TTS-Flash 是阿里云通义团队推出的一款旗舰级文本转语音(Text-to-Speech, TTS)模型,它继承了Qwen系列模型的先进AI技术。
核心功能
多音色支持: 提供多种人物音色选择。
多语言能力: 具备卓越的中英语音稳定性,并支持多种语言的合成。
多方言覆盖: 能够处理多种方言的文本输入。
高表现力拟人音色: 生成的语音自然、富有表现力。
项目官网:https://qwen.ai/blog?id=b4264e11fb80b5e37350790121baf0a0f10daf82
Qianfan-VL – 百度
百度千帆-VL (Qianfan-VL) 是百度推出的一系列通用多模态大语言模型,专为企业级多模态应用场景设计。
核心功能
- 多模态理解与交互: 能够深入分析并理解图像、文本等多种模态数据。
- 企业级应用优化: 针对文档识别,数学问题求解、图表理解、表格识别等核心任务进行特定优化。
- 高性能推理部署: 支持通过Transformer和vLLM部署,并提供OpenAI兼容API接口。
技术原理
- 多模态大模型架构: 融合了先进的视觉编码器和语言解码器。
- 多任务数据合成管线: 结合传统计算机视觉模型与程序化生成方法。
- 四阶段渐进式训练: 采用分阶段、迭代优化的训练策略。
应用场景
智能文档处理: 适用于票据识别、合同分析、报告解读等。
智能客服与虚拟助手: 结合图像信息,提供更精准的交互体验。
工业质检与安防监控: 进行缺陷检测、目标识别。
项目官网:https://baidubce.github.io/Qianfan-VL/
GitHub仓库:https://github.com/baidubce/Qianfan-VL
LongCat-Flash-Thinking – 美团推理模型
LongCat-Flash-Thinking是美团团队推出的一款拥有5600亿参数的大型推理模型(LRM),其核心特点是采用了创新的专家混合(MoE)架构。
核心功能
- 通用推理能力: 涵盖数学、逻辑、编码、指令遵循等多种通用推理任务。
- 高级推理支持: 尤其强调形式推理和智能体(Agentic)推理能力。
- 高效智能体任务处理: 在智能体任务中表现卓越。
技术原理
LongCat-Flash-Thinking采用混合专家(MoE)架构,总参数量达5600亿。其关键创新在于动态计算系统,能够根据当前上下文、效率和性能需求,动态激活186亿至313亿个参数进行推理。
- GitHub仓库:https://github.com/meituan-longcat/LongCat-Flash-Thinking
- 技术论文:https://github.com/meituan-longcat/LongCat-Flash-Thinking/blob/main/tech_report.pdf
DeepSeek-R1-Safe – 浙大联合华为推出的安全大模型
DeepSeek R1 Safe是DeepSeek公司推出的一款以推理能力为核心的大型语言模型,旨在提供高性能的AI推理服务。该模型在公开基准测试中表现出色,但其安全性与对抗性攻击的抵御能力受到广泛关注。
核心功能
- 高级推理任务: 专门设计用于解决复杂的推理问题。
- 代码生成与执行: 支持生成代码并提供奖励函数以评估代码执行成功率。
- 透明的推理过程: 不同于某些黑盒模型,DeepSeek R1能公开展示其推理步骤。
技术原理
自提示(Self-prompting): 采用类似ChatGPT o1的自提示机制。
强化学习(Reinforcement Learning, RL): 基于DeepSeek-V3基础模型进行后训练。
高质量CoT(Chain-of-Thought)数据训练: 利用从其他高性能模型中提取的高质量思维链示例进行训练。
HuggingFace模型库:https://huggingface.co/decart-ai/Lucy-Edit-Dev
混元3D-Omni
Hunyuan3D-Omni(混元3D-Omni)是腾讯混元3D团队推出的一个统一框架,旨在实现精细化、可控的3D资产生成。
核心功能
- 多模态可控3D生成: 支持文本、图像、深度图,法线图等多种控制信号作为输入。
- 统一控制信号表示: 引入Omni-Control,将不同模态的控制信号统一编码。
- 高质量3D资产输出: 能够生成高分辨率、多样化的3D模型。
技术原理
Hunyuan3D-Omni的核心在于其基于Hunyuan3D 2.1扩散模型架构,并引入了Omni-Control这一通用控制信号表示。
- GitHub仓库:https://github.com/Tencent-Hunyuan/Hunyuan3D-Omni
- HuggingFace 模型库:https://huggingface.co/tencent/Hunyuan3D-Omni
- arXiv技术论文:https://arxiv.org/pdf/2509.21245
混元3D-Part
Hunyuan3D-Part是腾讯混元实验室推出的一个开源、部分级3D生成模型。该平台旨在通过文本描述、单一或多张图像以及草图,快速生成高质量、精细化、带纹理和骨骼的3D模型。
核心功能
- 部分级3D生成: 实现对3D模型的精细化部分控制与生成。
- 多模态输入: 支持从文本、图像(单张或多张)和草图等多种形式输入生成3D模型。
- 高保真输出: 能够生成细节丰富、带有高质量纹理且可动画的3D模型。
技术原理
AI驱动的3D生成: 运用先进的人工智能技术进行三维模型创建。
扩散模型架构: Hunyuan3D 2.0/2.1版本采用基于扩散Transformer的大规模形状生成模型。
跨领域融合: 整合图像理解、3D几何处理和自然语言处理能力。
Github仓库:https://github.com/Tencent-Hunyuan/Hunyuan3D-Part
HuggingFace模型库:https://huggingface.co/tencent/Hunyuan3D-Part
混元图像3.0
腾讯混元图像3.0 (HunyuanImage 3.0) 是腾讯推出并开源的原生多模态图像生成模型。该模型参数规模高达80B,是目前开源领域中性能表现突出、参数量最大的文生图(text-to-image)模型。
核心功能
- 文本到图像生成: 依据用户提供的文本提示词,生成高质量、符合描述的图像。
- 原生多模态处理: 模型能够理解并融合多种模态信息进行图像生成。
- 图像分辨率自适应: 在自动模式下,模型能根据输入提示词自动预测并生成合适分辨率的图像。
技术原理
HunyuanImage 3.0 基于原生多模态、自回归的**混合专家(Mixture-of-Experts, MoE)**架构构建,其参数规模达到800亿。
- Github仓库:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
- Hugging Face模型库:https://huggingface.co/tencent/HunyuanImage-3.0
LONGLIVE – 英伟达视频生成
LongLive是由英伟达(NVIDIA)等顶尖机构联合推出的实时交互式长视频生成框架。它是一个开源项目,旨在通过用户输入的连续提示词,实时生成高质量、用户引导的长视频内容。
核心功能
- 实时长视频生成: 能够根据用户输入实时生成长达数分钟的视频。
- 交互式生成: 支持用户通过连续的提示词序列,对视频生成过程进行引导和控制。
- 用户引导式创作: 允许用户在生成过程中调整和细化内容。
技术原理
LongLive框架主要基于帧级自回归(AR)模型。
KV-recache机制: 用于高效管理和重用关键帧信息。
流式长视频微调(Streaming Long Tuning): 针对长视频特点进行模型微调。
短窗口注意力机制(Short Window Attention): 结合帧间注意力,优化计算效率。
GitHub仓库:https://github.com/NVlabs/LongLive
HuggingFace模型库:https://huggingface.co/Efficient-Large-Model/LongLive-1.3B
KAT-Dev-32B – 快手Kwaipilot代码大模型
KAT-Coder 是一个先进的代码智能模型,由快手 AI 团队(Kwaipilot)推出,致力于通过多阶段训练优化,为开发者提供强大的编程辅助。
核心功能
- 智能代码生成与辅助: 提供高效的代码编写辅助。
- 多阶段训练优化: 包含 mid-training,监督微调 (SFT)、强化微调 (RFT) 和大规模智能体强化学习 (RL) 阶段。
- SWE-Bench Verified 性能: 在代码基准测试中表现出色。
技术原理
KAT-Coder 的技术核心在于其独特的多阶段训练范式。首先,模型经历一个mid-training 阶段奠定基础代码理解能力,随后进行监督微调 (SFT),再引入强化微调 (RFT),最后通过大规模智能体强化学习 (RL) 进行深度优化。
- 项目官网:https://kwaipilot.github.io/KAT-Coder/
JoySafety – 京东大模型安全框架
JoySafety 是京东开源的大模型安全框架,旨在为企业提供成熟、可靠、免费的大模型内容安全防护方案。
核心功能
- 大模型内容安全防护: 对用户输入(Prompt)和模型生成回复进行全面安全判别。
- 多维度原子能力检测: 集成敏感词过滤,知识检索、RAG和 多轮对话安全检测等多种细粒度安全能力。
- API服务与策略编排: 提供标准化的对外API服务接口。
技术原理
多模态预训练模型集成: 框架底层融合了BERT、FastText、Transformer等多种预训练模型作为原子能力模块。
大模型指令微调 (Instruction Tuning): 基于 gpt-oss-20b 大型语言模型进行指令微调。
微服务架构设计: 系统采用模块化微服务架构。
GitHub仓库:https://github.com/jd-opensource/JoySafety
HuggingFace模型库:https://huggingface.co/jd-opensource/JSL-joysafety-v1
Lynx – 字节个性化视频生成模型
Lynx是由字节跳动(ByteDance)开发并开源的高保真个性化视频生成模型。它能够根据用户提供的一张静态图像,生成高质量、高保真度的个性化视频,同时有效保留视频中主体的身份和特征。
核心功能
- 个性化视频生成: 能够从单一输入图像出发,生成具有特定人物或对象特征的动态视频。
- 高保真度输出: 确保生成视频的视觉质量高,细节丰富。
- 主体身份保持: 在视频生成过程中,精确地维持输入图像中主体的身份特征。
技术原理
Lynx模型基于Diffusion Transformer (DiT) 架构构建。DiT是一种结合了扩散模型和Transformer的生成模型,利用Transformer的强大建模能力处理图像或视频数据。
- 项目官网:https://byteaigc.github.io/Lynx/
- Github仓库:https://github.com/bytedance/lynx
- HuggingFace模型库:https://huggingface.co/ByteDance/lynx
DeepSeek-OCR
DeepSeek-OCR 是由 DeepSeek-AI 开发的一个光学字符识别(OCR)模型,专注于"上下文光学压缩"(Contexts Optical Compression)。
核心功能
- 图像到文本转换 (Image-to-Text Conversion): 能够从图像文件中识别并提取文本内容。
- 多语言支持 (Multilingual Support): 在Hugging Face平台被标记为支持多语言。
- 加速推理 (Accelerated Inference): 支持 vLLM 加速模型推理。
技术原理
DeepSeek-OCR 基于先进的视觉-语言(Vision-Language)模型架构,采用 transformers 库中的 AutoModel 和 AutoTokenizer 进行模型的加载和初始化。
- GitHub仓库:https://github.com/deepseek-ai/DeepSeek-OCR
- HuggingFace模型库:https://huggingface.co/deepseek-ai/DeepSeek-OCR
PaddleOCR-VL
PaddleOCR-VL是百度飞桨团队推出的一个最先进(SOTA)且资源高效的文档解析模型,其核心是超轻量级的PaddleOCR-VL-0.9B视觉-语言模型(VLM)。
核心功能
- 文档结构化解析: 能够准确识别并解析文档中的各种复杂元素。
- 多语言支持: 高效支持109种不同的语言进行识别和解析。
- 高性能与资源效率: 模型参数量仅为0.9B,可在普通CPU上运行。
技术原理
PaddleOCR-VL的核心技术基于其紧凑而强大的视觉-语言模型PaddleOCR-VL-0.9B。该模型将NaViT风格的动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型深度融合。
- 项目官网:https://ernie.baidu.com/blog/zh/posts/paddleocr-vl/
- HuggingFace模型库:https://huggingface.co/PaddlePaddle/PaddleOCR-VL
LongCat-Video – 美团开源的AI视频生成模型
LongCat-Video是美团LongCat团队开源的136亿参数视频生成基础模型。它是一个强大的AI模型,能够将文本和图像转化为高质量的视频。
核心功能
- 文本到视频生成 (Text-to-Video Generation):根据输入的文字描述生成相应的视频内容。
- 图像到视频生成 (Image-to-Video Generation):将静态图像转化为动态视频。
- 视频编辑与优化 (Video Editing and Optimization):通过AI技术提升视频的视觉质量、运动质量和文本对齐度。
技术原理
LongCat-Video采用136亿参数的Transformer架构作为其基础模型。其关键技术原理是利用多奖励强化学习优化 (Multi-reward Reinforcement Learning Optimization),特别是Group Relative Policy Optimization (GRPO) 方法。
- 项目官网:https://meituan-longcat.github.io/LongCat-Video/
- Github仓库:https://github.com/meituan-longcat/LongCat-Video
Lumine – 字节跳动推出的3D开放世界通用AI智能体
Lumine是字节跳动推出的通用AI智能体,旨在3D开放世界环境中实现实时感知、推理和行动。它能够像人类一样与复杂多变的虚拟世界进行交互。
核心功能
- 实时感知与理解: 能够实时感知3D开放世界环境中的视觉信息。
- 自主推理与决策: 基于感知信息进行高级推理,规划并执行复杂任务。
- 类人交互与行动: 通过"视觉推理"与游戏进行交互。
- 零样本跨游戏泛化: 无需针对特定游戏进行微调,即可在不同3D开放世界游戏中展现通用能力。
技术原理
Lumine基于视觉-语言模型(VLM)构建,具体采用了Qwen2-VL-7B-Base模型。
视觉-语言模型(VLM): 作为核心认知引擎。
四层架构设计: 受人脑记忆机制启发,包含代理层等结构。
项目官网:https://www.lumine-ai.org/
arXiv技术论文:https://arxiv.org/pdf/2511.08892
InfinityStar – 字节跳动推出的高效视频生成模型
InfinityStar是由字节跳动(FoundationVision)推出的一款高效视频生成模型。它旨在通过统一的时空自回归框架,实现高分辨率图像和动态视频的快速合成。
核心功能
- 高分辨率图像生成: 能够生成细节丰富的高质量图像。
- 动态视频合成: 具备快速生成流畅、逼真动态视频的能力。
- 统一的时空自回归框架: 将图像和视频生成整合到统一的模型架构中。
技术原理
InfinityStar采用了统一的时空自回归框架(unified spatio-temporal autoregressive framework)。其核心技术包括时空金字塔结构(spatio-temporal pyramid structure)。
- Github仓库:https://github.com/FoundationVision/InfinityStar
- HuggingFace模型库:https://huggingface.co/FoundationVision/InfinityStar
SmartResume – 阿里开源的智能简历解析工具
SmartResume是阿里巴巴开源的一款智能简历解析工具。它旨在解决传统简历处理中数据不完整、非结构化等问题。
核心功能
- 多格式简历解析: 支持PDF、图片、Word等多种主流简历文件格式。
- 文本信息提取: 能够从简历中进行OCR文本提取和PDF元数据解析。
- 版面检测与结构化: 实现简历版面检测,并利用大型语言模型(LLM)进行智能结构化处理。
技术原理
SmartResume的核心技术原理结合了多种先进的AI和数据处理方法:
光学字符识别 (OCR): 用于从图片和扫描的PDF中提取文本信息。
版面检测 (Layout-aware parsing): 通过计算机视觉技术识别简历的布局结构。
大型语言模型 (LLM) 智能结构化: 运用先进的自然语言处理技术。