LLM训练框架模块构建了覆盖全栈的大模型训练生态系统,集成20+专业训练框架和工具。核心框架包括:魔塔ms-swift(支持500+ LLMs和200+ MLLMs的全参数/PEFT训练)、Unsloth(2-5倍加速,80%内存节省)、英伟达Megatron-LM(超大规模transformer训练)、微软DeepSpeed(ZeRO优化器)、ColossalAI(高性能分布式训练)、Meta FairScale、LLaMA-Factory(WebUI界面,支持100+模型)、书生XTuner等。
先进算法涵盖GaLore梯度低秩投影、BAdam内存高效优化、APOLLO、Adam-mini、Muon等前沿优化器。实验监控提供MLflow、WandB、SwanLab等专业工具。配套Flash Attention、Liger Kernel等加速技术,以及Easy Dataset数据构造工具,形成从数据准备、模型训练到实验管理的完整闭环。
2.大模型训练框架.md
0.ms-swift-魔塔训练框架
0.unsloth
- Megatron英伟达
1.ColossalAI
1.DeepSpeed-微软
1.FairScale-meta
1.Horovod
1.LLaMA-Factory
1.LLaMA-Factory/easy-data
1.xtuner-书生浦源
1.实验监控
1.实验监控/SwanLab
1.模型训练-实用技巧
1.训练先进算法
2.Firefly
2.MMEngine
2.fastAI
3.openai-在线微调
0.ms-swift-魔塔训练框架
简介
ms - swift是ModelScope社区提供的用于大语言模型和多模态大模型微调与部署的官方框架。它支持500 +大模型和200 +多模态大模型的训练、推理、评估、量化和部署等,集成了多种训练技术和人类对齐训练方法,还提供基于Gradio的Web UI和丰富的最佳实践。同时,还介绍了深度学习入门知识,包括模型推理、预训练范式、推理过程、PyTorch框架等内容。
核心功能
模型支持:支持500 +纯文本大模型、200 +多模态大模型的训练、推理、评估、量化和部署。
训练技术:集成轻量级技术和人类对齐训练方法。
加速与优化:支持vLLM、SGLang和LMDeploy加速推理、评估和部署模块,支持多种量化技术。
功能拓展:提供Web UI,支持自定义模型、数据集和组件。
技术原理
模型构建:由复杂数学公式构成,通过大量神经元及其他公式组合,在模型初始化时设置参数,利用数据训练调整参数以拟合数据。
训练方式:预训练利用大量未标注数据让模型学习文字通用逻辑;微调使用标注数据使模型具备问答能力;人类对齐借助含正确与错误答案的数据让模型输出符合人类需求。
推理过程:将输入文字转换为向量矩阵,经模型计算得到向量,概率化后选取最大值索引对应的文字,自回归生成后续文字,遇到结束字符停止。
框架支持:基于PyTorch框架进行向量运算、求导等操作,通过修改模型结构实现轻量调优。
应用场景
科研领域:研究人员进行大模型和多模态大模型的训练、评估和优化。
工业应用:企业对模型进行微调、推理和部署,应用于智能客服、内容生成等场景。
教育学习:学生和爱好者学习深度学习和大模型相关知识。
modelscope-classroom/LLM-tutorial/A.深度学习入门介绍.md at main · modelscope/modelscope-classroom
0.unsloth
简介
Unsloth 的微调指南,介绍了大语言模型微调的基础知识,包括理解微调概念、选择合适模型与方法、准备数据集、了解模型参数、安装与配置、训练与评估、运行与保存模型等内容,并给出了示例和建议。
核心功能
对预训练大语言模型进行微调,更新知识、定制行为、优化特定任务性能。
支持多种微调方法,如 QLoRA 和 LoRA。
提供模型训练和评估功能,可调整参数避免过拟合和欠拟合。
支持模型的运行和保存,可将微调后的模型保存为 LoRA 适配器。
技术原理
微调基于预训练的大语言模型,在特定数据集上继续训练,更新模型权重以适应特定任务。
QLoRA 方法结合 LoRA 和 4 位量化,减少内存使用,可处理大型模型。
通过调整学习率、训练轮数等超参数,平衡模型的准确性和泛化能力。
应用场景
训练大语言模型预测标题对公司的影响。
利用历史客户交互数据实现更准确和个性化的响应。
在法律文本上微调大语言模型,用于合同分析、案例研究和合规检查。
unslothai/unsloth: Finetune Llama 3.1, Mistral, Phi & Gemma LLMs 2-5x faster with 80% less memory
1. Megatron英伟达
简介
NVIDIA的Megatron-LM与Megatron-Core项目聚焦于大规模训练Transformer模型的GPU优化技术。Megatron-LM是研究型框架,Megatron-Core是GPU优化技术库,具有系统级优化创新和模块化API。项目提供多种模型预训练脚本,支持多类型并行训练,还涉及模型评估、优化与部署等功能。
核心功能
模型训练:支持BERT、GPT、T5等模型的预训练,可进行分布式训练,采用数据和模型并行策略。
内存优化:提供激活检查点与重计算、分布式优化器等技术,减少内存使用。
性能提升:运用FlashAttention算法加速训练,通过并行通信与计算重叠提高可扩展性。
模型评估:涵盖多种下游任务评估,如WikiText困惑度、LAMBADA填空准确率等。
模型转换:支持模型类和检查点格式的转换,方便不同场景使用。
技术原理
并行技术:采用数据并行、张量模型并行、序列并行、流水线模型并行等,提升训练效率。
激活重计算:分选择性和全量重计算,根据内存情况选择不同粒度和方法。
分布式优化器:将优化器状态均匀分布在数据并行等级上,减少内存占用。
FlashAttention:一种快速且内存高效的算法,用于计算精确注意力。
应用场景
自然语言处理:语言模型预训练、文本生成、问答系统等。
模型研究:研究人员用于探索大规模模型训练技术和优化策略。
工业应用:企业级AI平台进行模型开发和部署,如NVIDIA NeMo。
NVIDIA/Megatron-LM: Ongoing research training transformer models at scale
1.ColossalAI
简介
Colossal-AI 是一个统一的深度学习系统,旨在让大 AI 模型训练更便宜、快速且易实现。它提供分布式训练和推理的并行组件,支持多种并行策略和异构内存管理,在多个领域有应用案例,还提供命令行界面和配置工具。
核心功能
并行训练:支持数据并行、流水线并行、张量并行等多种策略,可加速大模型训练。
异构内存管理:如 PatrickStar,优化内存使用。
推理加速:提升大模型推理速度。
项目管理:提供命令行界面管理项目。
配置灵活:可按需定义项目配置。
技术原理
Colossal-AI 引入统一接口,将顺序代码扩展到分布式环境,支持数据、流水线、张量和序列并行等训练方法,并集成异构训练和零冗余优化器(ZeRO),通过自动并行策略和内存管理技术,提高训练和推理效率。
应用场景
自然语言处理:训练 GPT、LLaMA 等大语言模型。
计算机视觉:加速 Stable Diffusion 等模型训练和推理。
生物医学:加速 AlphaFold 蛋白质结构预测。
推荐系统:利用缓存嵌入训练更大的嵌入表。
hpcaitech/ColossalAI: Making large AI models cheaper, faster and more accessible
ColossalAI/docs/README-zh-Hans.md at main · hpcaitech/ColossalAI
1.DeepSpeed-微软
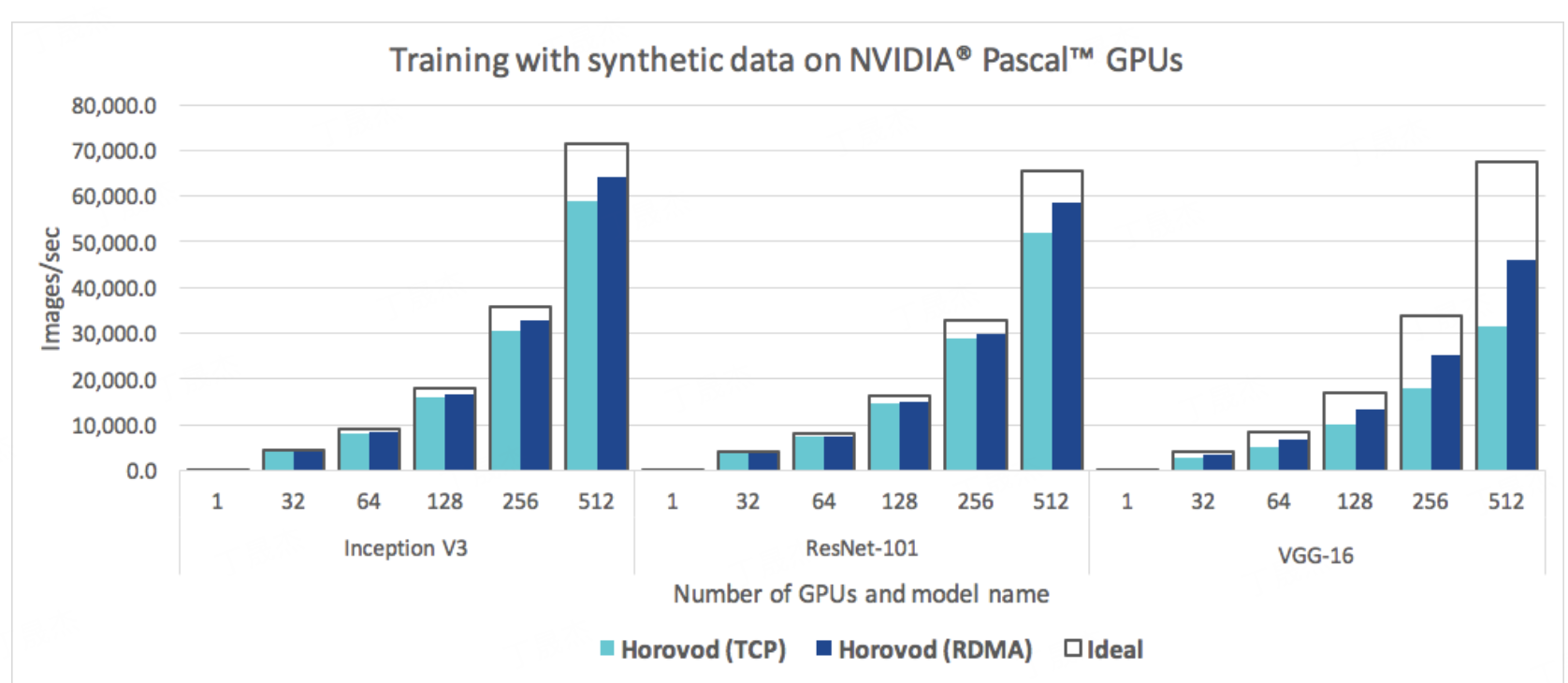
简介
DeepSpeed是微软推出的开源深度学习优化软件套件,是轻量级PyTorch包装器。它集合分布式训练、推断、压缩等高效模块,旨在提高大规模模型训练的效率和可扩展性,助力训练和推理万亿参数的密集或稀疏模型。
核心功能
分布式训练:支持混合精度、单GPU、多GPU和多节点训练,提供流水线并行、模型并行及3D并行。
优化器:提供Zero冗余优化器(ZeRO),可进行优化器状态、梯度和激活分区;有1-bit Adam、0/1 Adam和1-bit LAMB等低通信优化器。
内存优化:具备激活检查点、智能梯度累积、通信重叠等功能。
训练特性:有简化训练API、梯度裁剪、自动损失缩放等功能。
推理加速:结合并行技术和高性能自定义推理内核,实现低延迟和高吞吐量。
模型压缩:提供易于使用和灵活组合的压缩技术。
技术原理
并行策略:采用数据并行、张量并行、流水线并行,以及将三者结合的3D并行。
零冗余优化器(ZeRO):对优化器状态、梯度和参数进行分区,减少内存冗余;ZeRO-Offload将数据和计算从GPU卸载到CPU;ZeRO-Infinity利用NVMe磁盘空间突破GPU内存壁垒。
混合精度训练:内部处理混合精度训练的损失缩放。
稀疏注意力:支持长序列输入,提高执行速度。
应用场景
自然语言处理:训练大语言模型,如GPT、BERT等。
计算机视觉:用于图像分类、目标检测等任务。
科学研究:助力解决科学领域的复杂问题。
DeepSpeed/blogs/deepspeed-chat/chinese at master · microsoft/DeepSpeed
1.FairScale-meta
简介
FairScale 是一个由 Facebook Research 开发的 PyTorch 扩展库,旨在为高性能和大规模训练提供支持。它通过扩展 PyTorch 的基本功能,并集成最新的状态级(SOTA)扩展技术,帮助用户更高效地进行深度学习模型的训练。
核心功能
提供可组合模块和易用API,帮助研究人员在资源有限的情况下扩展模型。
提供FullyShardedDataParallel(FSDP)方法用于扩展大型神经网络模型。
集成SOTA扩展技术: 包含最新的分布式训练和模型并行策略,例如梯度累积、混合精度训练、模型并行等。
技术原理
FairScale 的核心技术原理在于其对 PyTorch 训练过程的底层优化和高级分布式策略的封装。它通过以下方式实现性能提升和规模扩展:
分布式训练(Distributed Training): 利用多GPU或多节点环境,将模型和数据分布到不同的计算资源上进行并行处理,从而加速训练并处理更大的模型。
混合精度训练(Mixed Precision Training): 结合使用FP16和FP32浮点格式,减少内存占用并加速计算,同时保持模型精度。
模型并行(Model Parallelism): 当模型过大无法放入单个GPU内存时,FairScale 支持将模型的不同层或部分分布到不同的GPU上。
优化器状态分片(Optimizer State Sharding): 将优化器的状态(如Adam的动量和方差)在不同的设备之间分片存储,显著减少每个设备的内存开销。
梯度累积(Gradient Accumulation): 通过累积多个小批量数据的梯度,模拟更大批量数据的训练效果,以处理内存限制下的超大批量训练。
检查点(Checkpointing): 智能地保存和加载模型状态,以便恢复训练或节省内存。
应用场景
大型语言模型(LLM)训练: 训练参数量巨大的Transformer类模型,如GPT-3、BERT等,需要高效的分布式训练能力。
大规模图像识别模型训练: 在ImageNet等大型图像数据集上训练ResNet、Vision Transformer等深度卷积神经网络和视觉Transformer。
科学计算和高性能AI研究: 需要处理海量数据和复杂模型的科研项目,例如气候模拟、药物发现等。
资源受限环境下的模型训练: 在GPU内存有限但需要训练大型模型时,通过 FairScale 的内存优化功能可以实现训练。
企业级AI解决方案部署: 在生产环境中部署需要快速迭代和训练的深度学习模型。
facebookresearch/fairscale: PyTorch extensions for high performance and large scale training.
1.Horovod

简介
Horovod 是由 LF AI & Data 基金会托管的分布式深度学习训练框架,支持 TensorFlow、Keras、PyTorch 和 Apache MXNet 等框架。其目标是让分布式深度学习变得快速且易于使用。
核心功能
分布式训练:可将单 GPU 训练脚本轻松扩展到多 GPU 并行训练。
性能优化:具备 Tensor Fusion 功能,可提高性能;支持自动性能调优。
多框架支持:支持 TensorFlow、Keras、PyTorch 和 Apache MXNet 等多种深度学习框架。
多环境运行:可在多种环境中运行,如 Docker、Kubernetes、Spark 等。
技术原理
Horovod 核心原理基于 MPI 概念,如 size、rank、local rank、allreduce、allgather、broadcast 和 alltoall 等。分布式优化器将梯度计算委托给原始优化器,使用 allreduce 或 allgather 对梯度进行平均,然后应用这些平均梯度。
应用场景
深度学习模型训练:加速大规模深度学习模型的训练过程。
云计算平台:在云计算平台上进行分布式训练,如 Microsoft Azure。
科研领域:帮助科研人员更高效地进行深度学习研究。
horovod/horovod: Distributed training framework for TensorFlow, Keras, PyTorch, and Apache MXNet.
1.LLaMA-Factory
简介
主要围绕LLaMA-Factory展开,它是简单易用且高效的大模型训练与微调平台,支持上百种预训练模型,涵盖多种训练算法、运算精度、优化算法等。同时介绍了基于Amazon SageMaker和LlamaFactory构建的一站式无代码模型微调部署平台Model Hub,降低技术门槛,加速AI应用开发。还给出了使用LLaMA-Factory进行Qwen3微调的实战指南。
核心功能
模型训练与微调:支持多种模型的(增量)预训练、(多模态)指令监督微调、奖励模型训练等多种训练方式。
运算精度多样:包括16比特全参数微调、冻结微调、LoRA微调和多种比特的QLoRA微调。
优化加速:集成GaLore、BAdam等优化算法,以及FlashAttention - 2和Unsloth等加速算子。
推理与评估:支持Transformers和vLLM推理引擎,提供mmlu、cmmlu、ceval等数据集的自动评测脚本。
实验监控:可通过LlamaBoard、TensorBoard等工具进行实验监控。
无代码部署:Model Hub提供可视化、无代码的方式支持大量并发实验,完成模型微调与部署。
技术原理
模型微调:基于LoRA、QLoRA等技术,在预训练模型基础上,通过少量可训练参数对模型进行微调,降低训练成本和资源需求。
加速算子:FlashAttention - 2通过优化注意力机制计算,减少内存访问和计算量;Unsloth通过改进矩阵乘法等运算,提升训练速度。
量化技术:如AQLM、AWQ、GPTQ等,将模型参数量化为低比特,减少内存占用和计算量。
应用场景
领域模型构建:利用先进预训练模型,结合特定领域数据,完成领域模型的构建。
角色扮演模型训练:通过微调提升模型在垂直领域的知识问答能力,如训练Llama 3.2角色扮演模型。
翻译模型优化:结合特定数据对翻译模型进行微调,提高翻译质量和效率。
大模型评测:对大模型进行自动评测,评估模型在不同任务上的性能和泛化能力。
hiyouga/LLaMA-Factory: 官方A WebUI for Efficient Fine-Tuning of 100+ LLMs (ACL 2024)
hiyouga/ChatGLM-Efficient-Tuning: Fine-tuning ChatGLM-6B with PEFT | 基于 PEFT 的高效 ChatGLM 微调
基于 Amazon SageMaker 和 LLaMA-Factory 打造一站式无代码模型微调部署平台 Model Hub | 亚马逊AWS官方博客
基于LLaMA-Factory和Easy Dataset的Qwen3微调实战:从数据准备到LoRA微调推理评估的全流程指南_llamafactory qwen3-CSDN博客
easy-data
简介
Easy Dataset 是专为创建大型语言模型(LLM)微调数据集设计的应用程序,提供直观界面,可上传特定领域文件、智能分割内容、生成问题和高质量训练数据。其生成的结构化数据集兼容遵循 OpenAI 格式的 LLM API,让模型微调简单高效。LLaMA Factory 是开源低代码大模型微调框架,集成多种微调技术,支持零代码微调。
核心功能
文档处理:智能识别处理 PDF、Markdown、DOCX 等格式文件。
文本分割:支持多种智能算法和自定义可视化分段。
问题生成:从文本片段提取相关问题。
标签构建:为数据集构建全局领域标签。
答案生成:用 LLM API 生成答案和思维链。
灵活编辑:可随时编辑问题、答案和数据集。
数据导出:支持多种格式和文件类型导出。
模型兼容:兼容遵循 OpenAI 格式的 LLM API。
自定义提示:可添加自定义系统提示。
技术原理
通过集成多种 LLM API(如 Ollama、OpenAI 等),利用核心库和工具实现文档处理、文本分割、问题与答案生成。借助提示词模板引导模型响应,使用数据库操作管理项目数据。
应用场景
模型微调:为各类遵循 OpenAI 格式的 LLM 提供高质量微调数据集。
领域知识学习:将特定领域文件转化为结构化数据,助力模型学习领域知识,如从互联网公司财报构建微调数据。
1.axolotl 训练框架
简介
Axolotl是一个旨在简化AI模型后训练流程的工具,支持多种主流模型(如LLaMA、Mistral、Mixtral等)及多样化训练方法(全微调、LoRA、QLoRA、QAT、偏好微调、强化学习等),具备易配置(单YAML文件管理全流程)、性能优化(Flash Attention、多GPU训练)、灵活数据集处理(本地/HuggingFace/云存储)及云就绪(Docker镜像/PyPI包)等特性,适用于从基础到高级的模型微调任务。
核心功能
多模型支持:兼容HuggingFace Transformers因果语言模型,覆盖LLaMA、Mistral、Pythia等主流模型。
多样化训练方法:支持全微调、LoRA、QLoRA、GPTQ、QAT(量化感知训练)、偏好微调(DPO/IPO等)、强化学习(GRPO)、多模态训练及奖励模型(RM/PRM)训练。
统一配置管理:通过单YAML文件实现数据集预处理、训练、评估、量化及推理的全流程管理。
性能优化:集成Flash Attention、Xformers、Liger Kernel等计算优化技术,支持多GPU(FSDP/DeepSpeed)、多节点(Torchrun/Ray)训练及序列并行(SP)。
灵活数据加载:支持本地文件、HuggingFace数据集及云存储(S3/Azure/GCP等)的数据集加载。
云适配性:提供Docker镜像及PyPI包,适配云平台与本地硬件环境。
技术原理
Axolotl基于HuggingFace Transformers框架,针对因果语言模型设计后训练流程。技术上集成参数高效微调(PEFT)技术(如LoRA/QLoRA),通过低秩矩阵分解减少可训练参数;采用Flash Attention、Xformers等注意力机制优化技术降低计算复杂度;结合FSDP(完全分片数据并行)、DeepSpeed等分布式训练框架实现多GPU/多节点扩展;支持序列并行(SP)以扩展上下文长度;通过YAML配置文件统一管理数据预处理(如alpaca格式解析)、模型加载(8bit/4bit量化)、训练超参数(学习率/批次大小)及后处理(LoRA权重合并)流程,确保全链路标准化。
应用场景
模型指令微调:基于alpaca等格式数据集,对LLaMA、Mistral等模型进行指令跟随训练。
多模态模型开发:支持图像-文本等多模态数据的联合微调。
奖励模型训练:用于生成式AI的偏好优化(如RM/PRM训练)。
量化模型优化:通过QAT(量化感知训练)提升模型推理效率。
强化学习调优:结合GRPO等强化学习方法优化模型生成质量。
云/本地开发:利用Docker镜像或PyPI包,在云平台或本地GPU环境快速启动训练任务。
1.xtuner-书生浦源
简介
XTuner是由InternLM开发的高效、灵活且功能丰富的大模型微调工具包。它支持多种大模型,如InternLM2、Llama 2/3等,能进行连续预训练、指令微调等。在不同时间节点不断增加新功能,支持新模型和训练算法,其输出模型可与部署、评估工具集成。
核心功能
模型支持:支持多种大模型及VLM,适配不同格式数据集。
训练算法:支持QLoRA、LoRA、全参数微调等多种算法。
训练类型:支持连续预训练、指令微调、代理微调。
交互与集成:支持与大模型聊天,输出模型可与部署、评估工具集成。
技术原理
高效性:支持在多种GPU上进行LLM、VLM预训练/微调,自动调度高性能算子,兼容DeepSpeed进行优化。
灵活性:设计良好的数据管道,能适应任何格式数据集,支持多种训练算法。
全功能:通过提供多种配置文件,支持不同类型的训练,并实现与其他工具的无缝集成。
应用场景
模型训练:对多种大模型进行高效微调,满足不同业务需求。
模型交互:与大模型进行聊天交互。
模型部署与评估:输出模型可用于部署和大规模评估。
1.实验监控
简介
MLflow是一个开源平台,旨在帮助机器学习从业者和团队应对机器学习过程的复杂性,专注于机器学习项目的全生命周期,确保各阶段可管理、可追溯和可复现。其核心组件包括实验跟踪、模型打包、模型注册、服务、评估和可观测性等。该平台可在多种环境中运行,如本地开发、Amazon SageMaker、AzureML和Databricks等。由于另一个链接内容获取失败,无法将其相关信息纳入简介。
核心功能
实验跟踪:提供API记录模型、参数和结果,通过交互式UI进行比较。
模型打包:采用标准格式打包模型及其元数据,保证可靠部署和可复现性。
模型注册:集中的模型存储、API和UI,协作管理模型全生命周期。
服务:支持将模型无缝部署到不同平台进行批量和实时评分。
评估:提供自动化模型评估工具,与实验跟踪集成记录性能。
可观测性:与多种GenAI库集成,支持调试和在线监控。
技术原理
MLflow通过一系列API和工具实现其核心功能。在实验跟踪中,利用API记录模型训练过程中的参数和结果,并存储在后端存储中,通过交互式UI展示和比较。模型打包采用标准格式,将模型和元数据封装,确保依赖版本等信息可追溯。模型注册使用集中存储和API管理模型的全生命周期。服务功能借助Docker、Kubernetes等平台的相关技术实现模型部署。评估工具通过自动化脚本计算模型性能指标。可观测性通过与GenAI库的集成和Python SDK实现跟踪和监控。
应用场景
机器学习实验管理:记录和比较不同实验的结果,优化模型参数。
模型部署:将训练好的模型部署到不同平台进行批量和实时预测。
模型评估:对模型性能进行自动化评估和可视化比较。
模型监控:在线监控模型的运行状态,及时发现问题。
mlflow/mlflow: Open source platform for the machine learning lifecycle
SwanLab
简介
SwanLab是一款开源、现代化设计的深度学习训练跟踪与可视化工具,支持云端/离线使用,适配30+主流AI训练框架。它提供实验跟踪、版本管理、可视化等功能,支持多人协作,可帮助AI开发团队改进模型训练流程。
核心功能
实验跟踪与记录:跟踪训练关键指标,记录超参数、日志、硬件信息等。
可视化:支持折线图、媒体图等多种图表,实时可视化训练进展。
框架集成:与主流AI训练框架轻松集成,只需少量代码即可开始使用。
硬件监控:实时监控CPU和GPU使用情况。
实验对比:通过表格对比不同实验差异,启发实验灵感。
团队协作:支持不同训练师在同一项目跑实验,打通沟通壁垒。
插件拓展:可通过插件扩展功能,如邮件通知、飞书通知等。
技术原理
SwanLab通过Python API嵌入到机器学习pipeline中,收集训练过程中的指标、超参数、日志等数据。它利用自身的可视化引擎将数据以图表形式展示,方便用户分析。同时,支持与多种主流框架集成,借助框架的特性实现分布式训练中的实验记录。在硬件监控方面,通过脚本获取CPU、GPU等硬件的系统级信息。
应用场景
模型训练:实时监控训练过程,辅助分析决策,提高模型迭代效率。
科研协作:团队成员共同构建最佳模型,加速实验进展。
教学实践:帮助学生理解模型训练过程,进行实验对比和分析。
工业应用:在企业中优化AI开发流程,提高协作效率。
1.模型训练-实用技巧
简介
该仓库提供了FlashAttention和FlashAttention - 2的官方实现。FlashAttention可实现快速且内存高效的精确注意力计算,具有IO感知特性;FlashAttention - 2则在此基础上有更好的并行性和工作分区。此外还推出了FlashAttention - 3的beta版本。项目介绍了使用方法、安装要求、不同GPU的支持情况等内容,并给出了性能对比和测试方法。
核心功能
注意力计算:实现缩放点积注意力(scaled dot product attention),支持多种参数设置,如因果掩码、滑动窗口、ALiBi等。
增量解码:通过
flash_attn_with_kvcache函数支持增量解码,可更新KV缓存。多查询和分组查询注意力:支持MQA/GQA,可通过设置不同的头数实现。
技术原理
IO感知:FlashAttention通过考虑内存输入输出(IO),优化注意力计算过程,减少内存访问,提高计算速度和内存效率。
并行性和工作分区:FlashAttention - 2进一步优化了并行性和工作分区,提升了计算速度。
应用场景
自然语言处理:在GPT等语言模型的训练和推理中,可加速注意力计算,减少内存占用,提高训练和推理效率。
深度学习模型:适用于需要注意力机制的各种深度学习模型,如Transformer架构的模型。
Dao-AILab/flash-attention: Fast and memory-efficient exact attention
linkedin/Liger-Kernel: Efficient Triton Kernels for LLM Training
1.训练先进算法
简介
主要围绕大语言模型训练中的优化器展开。APOLLO是为大语言模型预训练和全参数微调设计的内存高效优化器,兼具SGD的低内存成本与AdamW的性能;Adam - mini是Adam的精简版,能以少50%的内存实现与AdamW相当或更好的性能;BAdam通过依次解决块坐标优化子问题,在全参数微调时大幅降低内存需求;Muon是用于神经网络隐藏层的优化器,在训练速度和性能上有出色表现。
核心功能
APOLLO:在大语言模型训练中,以SGD般的内存成本实现AdamW级别的性能,支持FSDP,集成于多个框架。
Adam - mini:减少Adam中学习率资源以降低内存,在多种训练任务中表现优于AdamW。
BAdam:通过分块优化,降低大语言模型全参数微调的内存成本,且在MT bench中表现出色。
Muon:优化神经网络隐藏层权重,提升训练速度和性能,适用于大规模模型训练。
技术原理
APOLLO:结合低秩近似和优化器状态冗余减少,通过纯随机投影在低秩辅助空间近似通道梯度缩放因子。
Adam - mini:根据Hessian结构划分参数块,为每个块分配单一学习率,去除Adam中大部分学习率资源。
BAdam:顺序解决块坐标优化子问题,在小部分参数上运行Adam更新规则。
Muon:针对神经网络隐藏层特点进行优化,具体原理未详细说明。
应用场景
APOLLO:大语言模型的预训练和全参数微调。
Adam - mini:语言模型的预训练、监督微调、强化学习微调等。
BAdam:大语言模型的全参数微调,如Llama系列。
Muon:神经网络隐藏层优化,大规模语言模型训练。
jiaweizzhao/GaLore: GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
zhuhanqing/APOLLO: APOLLO: SGD-like Memory, AdamW-level Performance
KellerJordan/Muon: Muon optimizer: +>30% sample efficiency with <3% wallclock overhead
VeOmni – 字节跳动开源的全模态PyTorch原生训练框架
VeOmni 是字节跳动Seed团队开源的一款全模态分布式训练框架,基于PyTorch设计。它旨在以模型为中心,加速多模态大型语言模型(LLMs)的开发与训练,并支持任意模态模型的无缝扩展,提供模块化和高效的训练能力。
核心功能
全模态训练支持: 能够高效地进行单模态和多模态模型的预训练与后训练。
分布式并行训练: 灵活支持多种分布式并行策略的组合,优化大规模模型训练效率。
模型计算与并行解耦: 将分布式并行逻辑与模型计算过程解耦,增强了框架的灵活性和可配置性。
高吞吐性能: 能够以高吞吐量进行大规模模型训练,例如可实现每GPU每秒2800+ tokens的MoE模型训练。
“积木式”配置: 提供直观且易于配置的“积木式”训练方案,简化复杂分布式策略的部署。
技术原理
VeOmni 的核心技术原理是其模型中心化(Model-Centric)的设计理念和引入的分布式配方库(Distributed Recipe Zoo)。该框架将底层分布式并行策略(如数据并行、模型并行、流水线并行、专家并行等)从上层模型计算逻辑中抽象并解耦。这种架构允许用户像组装积木一样,灵活配置和组合不同的并行方案,以适应不同规模和模态(如文本、图像、音频等)的模型训练需求。基于PyTorch生态,VeOmni能够高效利用GPU资源,并通过优化并行策略,显著提升大规模模型,尤其是全模态MoE模型的训练吞吐量和扩展性。
应用场景
大规模多模态LLM训练: 用于加速和扩展全模态大型语言模型(LLMs)的预训练和微调。
多模态融合模型开发: 为研究人员和开发者提供高效平台,探索和构建涉及图像、文本、语音等多种模态融合的模型。
高性能计算集群应用: 适用于需要在大规模计算集群上进行高效分布式训练的企业和研究机构。
前沿AI模型研究: 便于AI研究人员实验和验证复杂的分布式训练策略对新型模型架构的性能影响。
GitHub仓库:https://github.com/ByteDance-Seed/VeOmni
arXiv技术论文:https://arxiv.org/pdf/2508.02317
2.Firefly
简介
Firefly是开源大模型训练项目,支持对Qwen2、Llama3等主流大模型进行预训练、指令微调和DPO,提供全量参数训练、LoRA、QLoRA高效训练方式,还整理开源了指令微调数据集及模型权重。
核心功能
支持多种主流大模型的预训练、指令微调和DPO。
提供全量参数训练、LoRA、QLoRA等训练方式。
支持使用Unsloth加速训练并节省显存。
整理并开源指令微调数据集。
开源Firefly系列指令微调模型权重。
技术原理
预训练采用经典自回归损失,每个位置token参与loss计算;指令微调仅计算assistant回复部分的loss。
利用LoRA、QLoRA等技术实现高效训练,减少参数量和显存占用。
通过配置文件管理训练参数,方便扩展和优化。
应用场景
大模型的预训练、指令微调和DPO训练。
中文或英文语言模型的训练,可根据需求选择不同数据集。
模型推理,提供多轮对话交互脚本。
2.MMEngine
简介
MMEngine 是基于 PyTorch 的深度学习模型训练基础库,作为 OpenMMLab 所有代码库的训练引擎,支持各研究领域的数百种算法,也可应用于非 OpenMMLab 项目。它集成主流大模型训练框架,支持多种训练策略,提供友好配置系统,涵盖主流训练监控平台。
核心功能
集成 ColossalAI、DeepSpeed、FSDP 等主流大模型训练框架。
支持混合精度训练、梯度累积、梯度检查点等多种训练策略。
提供纯 Python 风格和支持 JSON、YAML 的纯文本风格配置系统。
覆盖 TensorBoard、WandB、MLflow 等主流训练监控平台。
技术原理
基于 PyTorch 构建,通过集成大模型训练框架,利用其分布式训练、模型并行等特性提升训练效率。采用配置系统管理训练参数,支持多种格式配置文件,方便用户灵活配置。借助训练监控平台,实时记录和展示训练过程中的各项指标。
应用场景
计算机视觉领域,如训练生成对抗网络、语义分割模型。
自然语言处理等其他深度学习研究领域,用于模型训练和优化。
非 OpenMMLab 项目的深度学习模型训练。
2.fastAI
简介
Fastai是一个开源的深度学习库,旨在通过提供高层组件,使深度学习实践者能够快速便捷地在标准深度学习领域获得最先进(State-of-the-Art, SOTA)的结果。同时,它也为研究人员提供了灵活的低层组件,便于混合和匹配以探索和构建新的深度学习方法,且在易用性、灵活性和性能之间取得了良好的平衡。
核心功能
高层API与快速部署: 提供简洁高效的高层API,简化了深度学习模型的训练、验证和部署流程,使非专业人士也能快速上手。
低层可组合性: 允许用户访问和定制底层组件,为深度学习研究和高级用例提供高度灵活性。
SOTA模型实现: 封装了多种领域的最新深度学习实践,帮助用户在视觉、文本、表格数据和协同过滤等任务中达到领先性能。
数据处理管道: 内置强大的数据加载和预处理工具,支持高效的数据集管理和增强。
训练与评估工具: 提供一整套模型训练、回调函数、学习率查找器等工具,优化训练过程并便于性能评估。
技术原理
Fastai库采用分层架构设计,构建于PyTorch等主流深度学习框架之上,实现了从高层抽象到底层细节的逐步揭示。其核心原理包括:
渐进式学习(Progressive Disclosure): 允许用户从简单的API开始,随着理解深入逐步掌握更复杂的底层控制。
回调系统(Callback System): 提供灵活的回调机制,允许用户在训练周期的不同阶段插入自定义逻辑,如保存模型、调整学习率、实现早停等。
批处理转换与数据增强: 利用高效的数据管道和转换机制,在GPU上实时进行数据增强和预处理,提高训练效率。
迁移学习优化: 深度集成和优化了迁移学习技术,尤其是在自然语言处理和计算机视觉领域,使得在小数据集上也能取得优异表现。
应用场景
计算机视觉: 图像分类、目标检测、图像分割等任务的快速开发与SOTA模型训练。
自然语言处理: 文本分类、情感分析、语言模型训练和文本生成,特别是利用预训练模型进行迁移学习。
表格数据分析: 处理结构化数据,进行分类和回归任务。
深度学习教育与研究: 作为实践和教学深度学习的工具,帮助学生和研究人员快速验证新的想法和技术。
快速原型开发: 适用于企业和开发者需要快速构建和迭代深度学习解决方案的场景。
3.openai-在线微调
简介
主要围绕OpenAI微调模型展开。介绍了OpenAI提供线上微调GPT模型的功能,是学习微调的快速入门方式。包含微调概念、准备与上传数据、训练微调模型及使用微调模型等步骤,还给出使用微调模型进行多轮对话和流式输出的代码示例,同时展示了OpenAI开发者平台的快速入门及API请求示例。
核心功能
模型微调:通过额外训练微量数据集调整GPT模型输出,具有高质量回答、节省Token、降低延迟等优点。
数据处理:支持三种数据格式,可检查数据格式以保障训练效果。
模型训练:可在网站手动或用代码本地训练,训练时间因模型和样本量级而异。
模型使用:简单替换模型名称即可在多轮对话中使用微调模型。
API调用:可通过API进行请求获取模型响应。
技术原理
基于GPT模型,通过额外训练特定数据集,调整模型参数以改变输出结果。在数据处理上,需遵循特定格式要求,确保训练样本格式正确以保证训练效果。训练过程中,根据所选模型和训练样本量级,模型进行参数调整和优化。
应用场景
对话交互:用于聊天机器人,使回答更符合特定需求。
内容生成:如生成故事、文案等,可通过微调使生成内容风格更贴合要求。
智能客服:为用户提供更精准、个性化的服务。
MicroCoder – 微软联合剑桥等推出的大模型训练优化框架
周报归档:第 31 期 · 条目 1.8 · 2026-04-01 · 回看原周报
原始周报文件:
weekly_report_20260401_164414.md
MicroCoder是由微软亚洲研究院、剑桥大学等联合推出的新一代代码大模型训练优化框架,针对Qwen3等现代代码模型训练瓶颈,从算法、数据、评估、经验四个维度进行升级,可使训练效果较DeepCoder提升3倍,评估准确率提升25%,为代码模型研发提供高效解决方案。
1.8.1 核心功能
算法优化:通过MicroCoder-GRPO算法的条件截断掩码、动态温度调整、去除KL散度约束三项改进,优化强化学习训练流程,实现模型性能持续稳定提升。
高质量数据供给:提供含13K+真实竞赛题的MicroCoder-Dataset,经五维难度评估矩阵校准,困难题占比超50%,适配新一代模型能力。
高容错评估:MicroCoder-Evaluator采用6-7种方法组成的回退链验证机制,解决严格匹配导致的误判问题,评估准确率提升25%,训练速度提升40%。
训练经验沉淀:基于30余组受控实验,总结出覆盖七大维度的34条训练洞察,为模型训练提供可落地的实践指导。
1.8.2 技术原理
算法层面:MicroCoder-GRPO算法引入条件截断掩码机制,仅对满足最大长度、答案非错误、无尾部重复、随机抽取四个条件的输出执行掩码;采用多样性驱动的分阶段温度策略,先低温后高温提升训练效果;将KL散度权重设为0并提高裁剪比率,消除对输出多样性的抑制。
数据层面:采用四阶段流水线构建数据集,结合Bloom分类法与代码复杂度指标构建五维难度评估矩阵,由LLM三次独立打分后加权平均,再用模型实际通过率校准,提升困难题占比至50%以上。
评估层面:构建多方法回退链验证机制,依次尝试类型转换、浮点近似、空白规范化等多种比较策略,单个方法失败后自动切换,提升评估容错性与效率。
1.8.3 应用场景
代码大模型研发:适用于Qwen3等新一代推理代码模型的强化学习后训练,帮助研发团队突破传统训练方法瓶颈,提升模型性能。
竞赛编程模型优化:使用MicroCoder-Dataset的真实竞赛题数据,训练模型掌握复杂算法问题的推理与编码能力,适配算法竞赛场景。
企业代码助手开发:企业可基于其技术栈构建内部代码生成助手,通过精准评估框架与训练经验,提升模型在业务代码场景中的准确率与稳定性。
代码评估系统升级:现有代码评测平台可集成MicroCoder-Evaluator,解决严格匹配导致的误判问题,提升评测准确性与用户体验。
- GitHub仓库:https://github.com/ZongqianLi/MicroCoder
DataChef – 上海AI Lab联合复旦开源的AI数据配方生成模型
周报归档:第 31 期 · 条目 2.7 · 2026-04-01 · 回看原周报
原始周报文件:
weekly_report_20260401_164414.md
DataChef是上海AI实验室联合复旦大学开源的32B参数AI数据配方生成模型,通过强化学习自动生成大模型适配任务的完整数据处理流水线,输出可执行Python代码。该模型在数学、代码、金融等6个领域测试中性能逼近Gemini-3-Pro,部分任务超越工业级专家配方,推动数据工程从人工经验迈向自动化新范式。
2.7.1 核心功能
自动配方生成:根据目标任务和可用数据源,自动生成包含数据选择、清洗、合成等步骤的完整数据配方,无需人工编排操作流程。
可执行代码输出:直接输出Python数据处理代码,构建从原始数据到训练集的端到端自动化流水线,支持即训即用。
多环节数据处理:覆盖数据选择、清洗、增强、混合、去重等全流程操作,适配多领域多样化数据处理需求。
内置质量验证:通过Data Verifier代理奖励机制,实时评估数据质量并指导配方优化,降低传统数据工程的效果验证成本。
2.7.2 技术原理
将数据配方生成建模为端到端强化学习任务,采用GRPO算法进行在线强化学习优化。训练时通过冷启动监督微调初始化策略模型,解耦推理与代码生成提升稳定性;创新性设计Data Verifier代理奖励机制,将样本分为5个质量等级并基于采样子集评分,实现对数据质量的低成本实时预测,替代高成本的下游模型训练反馈。模型在覆盖19个领域、257个源数据集的任务池上训练,能在庞大代码组合空间中高效探索最优数据方案。
2.7.3 应用场景
领域大模型训练:为数学、金融、医疗等垂直领域自动生成适配数据配方,快速构建领域专用模型,减少人工数据处理成本。
数据工程自动化:替代依赖专家经验的手工数据筛选与配比流程,实现从原始数据到训练集的全流程自动化处理,提升数据处理效率。
模型后训练优化:为已有基座模型生成高质量微调数据,针对性提升模型在特定任务上的性能表现,无需重新采集数据。
低资源场景数据增强:在数据稀缺的领域,自动合成训练样本并优化数据配比,通过数据增强技术扩充有效训练数据规模。
GitHub仓库:https://github.com/yichengchen24/DataChe
HuggingFace模型库:https://huggingface.co/spaces/yichengchen24/DataChef
HuggingFace模型库:https://huggingface.co/yichengchen24/DataChef-32B
arXiv技术论文:https://arxiv.org/pdf/2602.11089
新Relax – 小红书开源的大模型强化学习训练引擎
周报归档:第 34 期 · 条目 2.2 · 2026-04-16 · 回看原周报
原始周报文件:
weekly_report_20260416_150700.md
Relax是小红书AI平台团队开源的全模态大模型强化学习训练引擎,基于Megatron-LM与SGLang构建,采用服务化异步架构实现训练与推理解耦。它支持文本、图像、音频、视频统一训练,在Qwen3-Omni-30B上验证了四模态稳定收敛,16×H800全异步模式较Colocate提速76%,较veRL提速20%,具备分钟级故障恢复与弹性扩缩容能力。
2.2.1 核心功能
全模态RL训练:统一支持文本、图像、音频、视频端到端强化学习后训练,已验证Qwen3-Omni系列稳定收敛超2000步。
异步训练架构:通过TransferQueue实现Rollout、Actor、Critic角色完全解耦并行,消除GPU空转,在Qwen3-Omni-30B上实现2倍训练速度提升。
服务化容错机制:每个RL角色作为独立Ray Serve部署,采用两级恢复策略,故障可在分钟级恢复且无需回退磁盘检查点。
弹性扩缩容:通过HTTP REST API动态增减Rollout推理引擎,支持同集群与跨集群联邦推理,资源调度灵活高效。
MoE高效支持:R3(Rollout Routing Replay)开销仅1.9%,解决MoE模型训练与推理路由不匹配问题,远低于竞品32%的开销。
2.2.2 技术原理
服务化异步架构:采用六层服务化设计,将Actor、Critic、Rollout等角色封装为独立Ray Serve服务,通过TransferQueue实现流式微批传输,计算与数据完全解耦,支持Colocate与全异步两种部署模式。
全模态数据处理:内建Omni Processor统一处理多模态数据,采用模态感知并行策略(ViT张量并行、编码器感知流水线放置),通过Field-Level存储实现同一样本不同字段独立读写,适配RL多阶段计算特性。
分布式权重同步:DCS(分布式检查点服务)实现NCCL/TCP双通道低延迟权重广播,支持GPU-GPU直接同步,避免磁盘IO开销,跨集群场景自动切换TCP传输。
异步一致性控制:通过max_staleness参数统一控制On/Off-Policy模式,StreamingDataLoader支持增量消费,DCS权重同步与训练计算重叠,平衡吞吐与策略新鲜度。
2.2.3 应用场景
全模态大模型后训练:针对Qwen3-Omni等支持多模态输入的大模型,通过RL后训练强化跨模态理解与生成能力,适用于通用AI助手开发。
Agentic智能体开发:训练具备多轮工具调用、环境交互能力的智能体,支持“执行→观察→决策”闭环,适用于视觉推理、代码执行等复杂任务。
视觉语言任务优化:对视觉问答(VQA)、图像描述、视频理解等任务进行RL后训练,提升模型多模态推理准确性,适用于智能医疗、自动驾驶等领域。
数学与代码推理增强:基于GRPO/GSPO算法,强化大模型数学求解、代码生成与逻辑推理能力,适用于教育、软件开发场景。
MoE模型高效训练:为Qwen3-30B-A3B等MoE架构模型提供低开销R3支持,降低训练成本,适用于超大规模大模型生产部署。
GitHub仓库:https://github.com/redai-infra/Relax
arXiv技术论文:https://arxiv.org/pdf/2604.11554
Relax – 小红书开源的大模型强化学习训练引擎
周报归档:第 35 期 · 条目 2.8 · 2026-04-19 · 回看原周报
原始周报文件:
weekly_report_20260419_095821.md
Relax是小红书AI平台团队开源的大模型强化学习训练引擎,基于Megatron-LM与SGLang构建,采用服务化容错架构和异步数据总线,实现Rollout、Actor、Critic角色完全解耦。它支持文本、图像、音频、视频统一训练,在Qwen3-Omni-30B上验证四种模态RL稳定收敛,16×H800全异步模式较Colocate提速76%,较veRL提速20%,具备分钟级故障恢复、弹性扩缩容及R3 MoE支持能力,已应用于Qwen3系列后训练。
2.8.1 核心功能
全模态RL训练:统一支持文本、图像、音频、视频的端到端强化学习后训练,已验证Qwen3-Omni系列稳定收敛。
异步训练架构:基于TransferQueue数据总线实现Rollout、Actor、Critic角色完全异步并行,消除GPU空转等待。
服务化容错:每个RL角色作为独立Ray Serve部署,具备故障隔离与分钟级自动恢复能力,支持训练不中断。
弹性扩缩容:通过HTTP REST API动态增减Rollout推理引擎,支持同集群与跨集群联邦推理资源调度。
分布式权重同步:DCS服务实现NCCL/TCP双通道低延迟权重广播,故障恢复无需回退磁盘Checkpoint。
Agentic多轮训练:原生支持多轮交互、工具调用、视觉上下文carry-over与Loss Masking,适配”执行→观察→决策”闭环。
2.8.2 技术原理
采用服务化六层架构(Entrypoints→Orchestration→Components→Engine→Backends→Distributed),通过TransferQueue实现异步数据总线,DCS实现分布式权重同步。将Actor、Critic、Rollout等角色封装为独立Ray Serve服务,通过TransferQueue进行流式微批传输,实现计算资源解耦与流水线并行,消除传统Colocate模式的串行等待瓶颈。内建Omni Processor统一处理图文音视频数据,支持模态感知并行与端到端异步流水,通过Field-Level存储机制允许同一样本的不同字段独立读写,适配RL多阶段计算特性。采用两级恢复策略(无状态角色原地重启、有状态角色全局恢复),配合DCS分布式Checkpoint服务实现GPU-GPU直接权重同步,避免磁盘IO开销,支持NCCL/TCP双通道适配跨集群拓扑。通过max_staleness参数灵活控制On/Off-Policy模式,StreamingDataLoader支持增量消费,DCS异步权重广播与训练计算重叠,在吞吐与策略新鲜度间取得平衡。
2.8.3 应用场景
全模态大模型后训练:统一优化支持文本、图像、音频、视频输入的Omni模型(如Qwen3-Omni),实现跨模态理解与生成能力强化,适用于大模型研发团队。
Agentic智能体开发:训练具备多轮工具调用、环境交互与自主决策能力的智能体,适配”执行→观察→决策”闭环任务(如DeepEyes多轮视觉推理),适用于智能体研发团队。
视觉语言任务优化:针对视觉问答(VQA)、图像描述、视频理解(NextQA)等任务进行RL后训练,提升多模态推理准确性,适用于计算机视觉与自然语言交叉领域研发团队。
数学与代码推理:通过GRPO/GSPO等算法增强大模型在数学问题求解(DAPO-Math)、逻辑推理与代码生成方面的能力,适用于AI推理能力研发团队。
MoE模型高效训练:支持Qwen3-30B-A3B等MoE架构的低成本R3重放训练,降低路由误差与计算开销,适用于大模型MoE架构研发团队。
GitHub仓库:https://github.com/redai-infra/Relax
arXiv技术论文:https://arxiv.org/pdf/2604.11554
📱 关注微信公众号「汀丶人工智能」
🔥 精选AI前沿资讯 | 📚 深度技术解读 | 💡 实战案例分享
🤝 欢迎加入AI Compass知识星球
🎯 更深入的内容 - 独家教程、项目实战、面试指导
⚡ 更高的更新频率 - 高频资讯推送、专家答疑、技术交流
🎁 限时优惠 - 与数千名AI学习者一起成长!
星球支持三天内免费退款,请放心订阅。
💬技术博客 | 📍社交媒体 |
{kind=link}