原文来源:Berryxia.AI
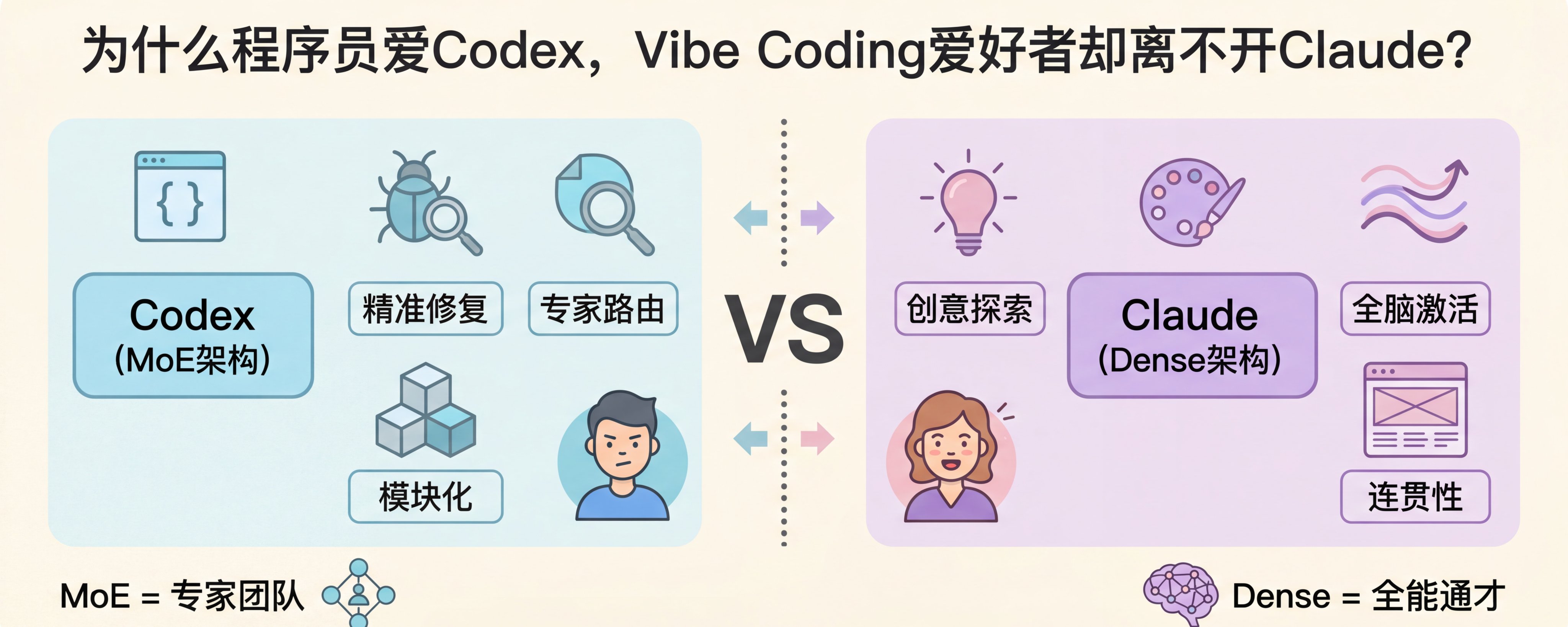
在 AI 辅助编程领域,一个流传已久的观点是:Codex(OpenAI 代码专用模型系列,现以 GPT-5.x Codex 为代表)深受传统程序员喜爱,尤其在修复 Bug 和生产级重构场景;
而 Claude(Anthropic 系列,如 Claude 4 / 4.6 Opus)则成为**“Vibe Coding"用户的首选。**
这一观点的核心归因于模型底层架构——Claude 是精细的稠密(Dense)Transformer,Codex 则采用**混合专家(Mixture of Experts,MoE)**设计,更适合模块化、精确的代码任务。
这一说法并非空穴来风,但远非全部真相。
它涉及了模型架构、训练哲学、产品形态以及真实开发者工作流的深层交织。
一、架构基础:Dense vs MoE 的本质区别
大型语言模型的核心是 Transformer 架构,其**前馈网络(Feed-Forward Network,FFN)**层决定计算方式:
1.1 Dense(稠密)模型 - Claude 主力架构
每一次前向传播(inference),所有参数都参与计算。模型像一个高度整合的"大脑”,对每个 token 都施加统一的、全连接的注意力与变换。
特点:
- 参数虽多,但激活一致性高
- 上下文连贯性极强
- 全脑激活式思考
1.2 MoE(混合专家)模型 - GPT-5.x Codex 核心
将 FFN 替换为多个**“专家子网络”(experts),由一个路由器(router)动态决定每个 token 只激活少数专家(通常 2-8 个)**。
核心公式:
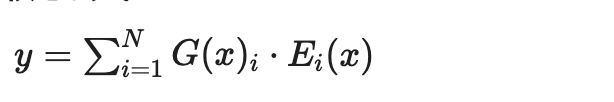
其中 是路由门控概率, 是第 个专家输出。
特点:
- 总参数规模可达万亿级
- 激活参数仅为 Dense 的几分之一
- 计算效率大幅提升
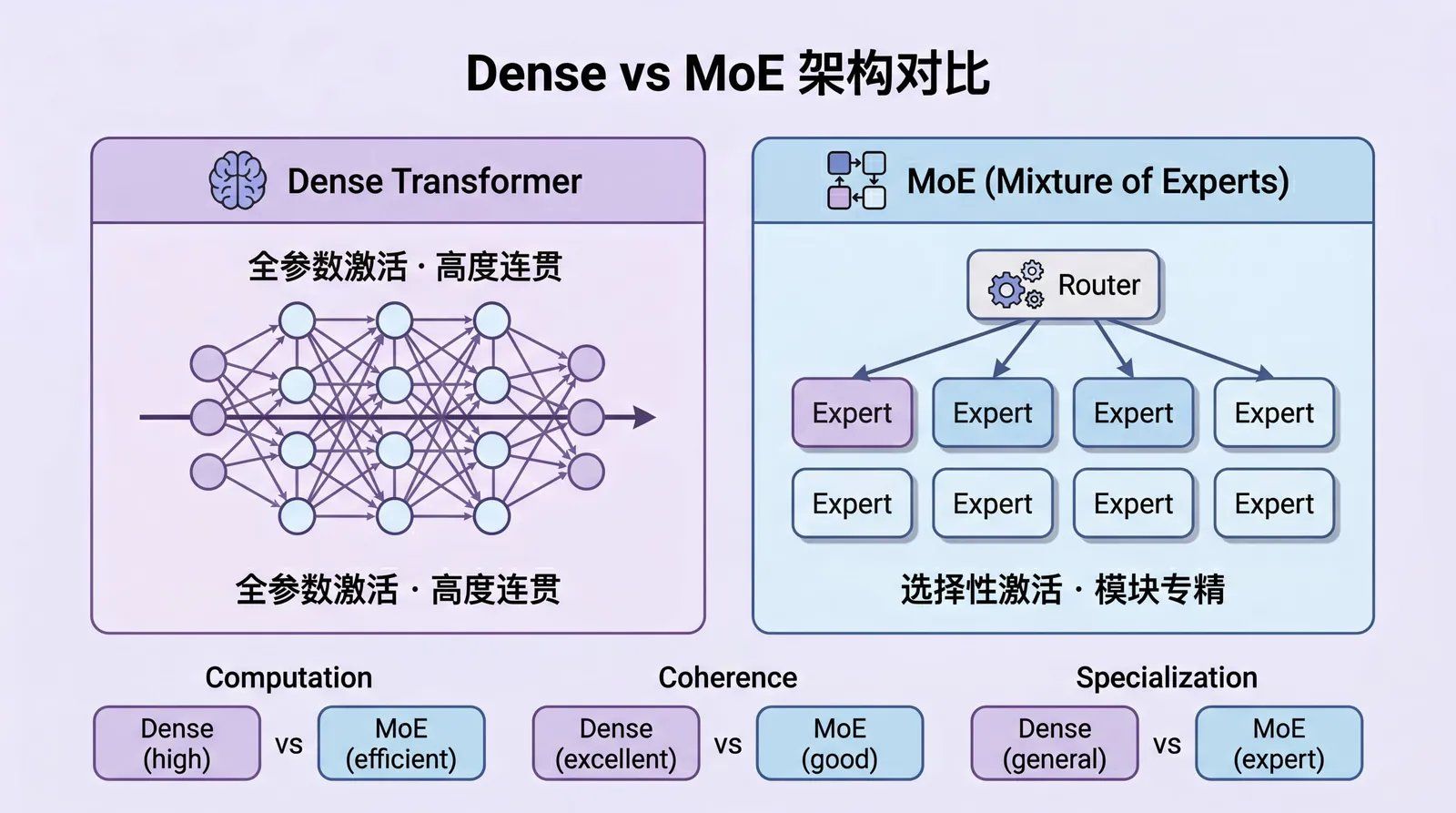
1.3 直观对比
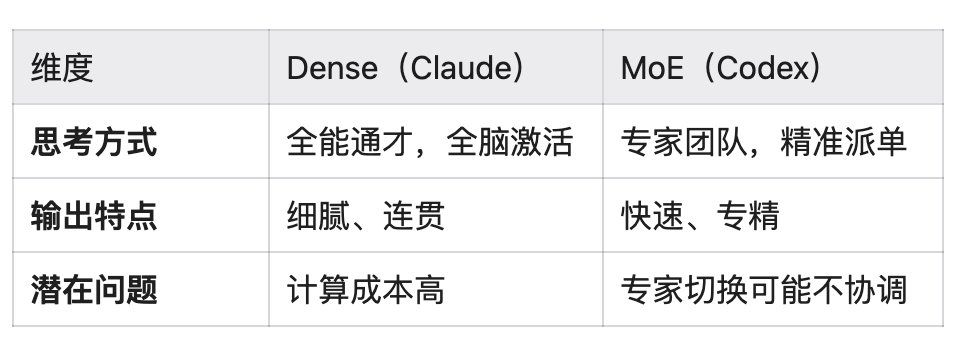
2026 年最新确认:
- Claude 4 系列仍以 Dense 为主
- OpenAI Codex 系列明确采用 MoE 或"路由双模型"(routed duo)设计,专为长时程代理式编码优化
二、Claude 模型(Dense):为什么是 Vibe Coding 用户的"最爱"?
2.1 什么是 Vibe Coding?
“Vibe Coding"由 Andrej Karpathy 于 2025 年初提出,指用自然语言描述"氛围与意图”(vibe),让 AI 自主生成原型、迭代产品,而非纠结语法细节。
典型示例:
“做一个像 Notion 一样的笔记 App,要有丝滑拖拽感和 AI 自动总结的能力。”
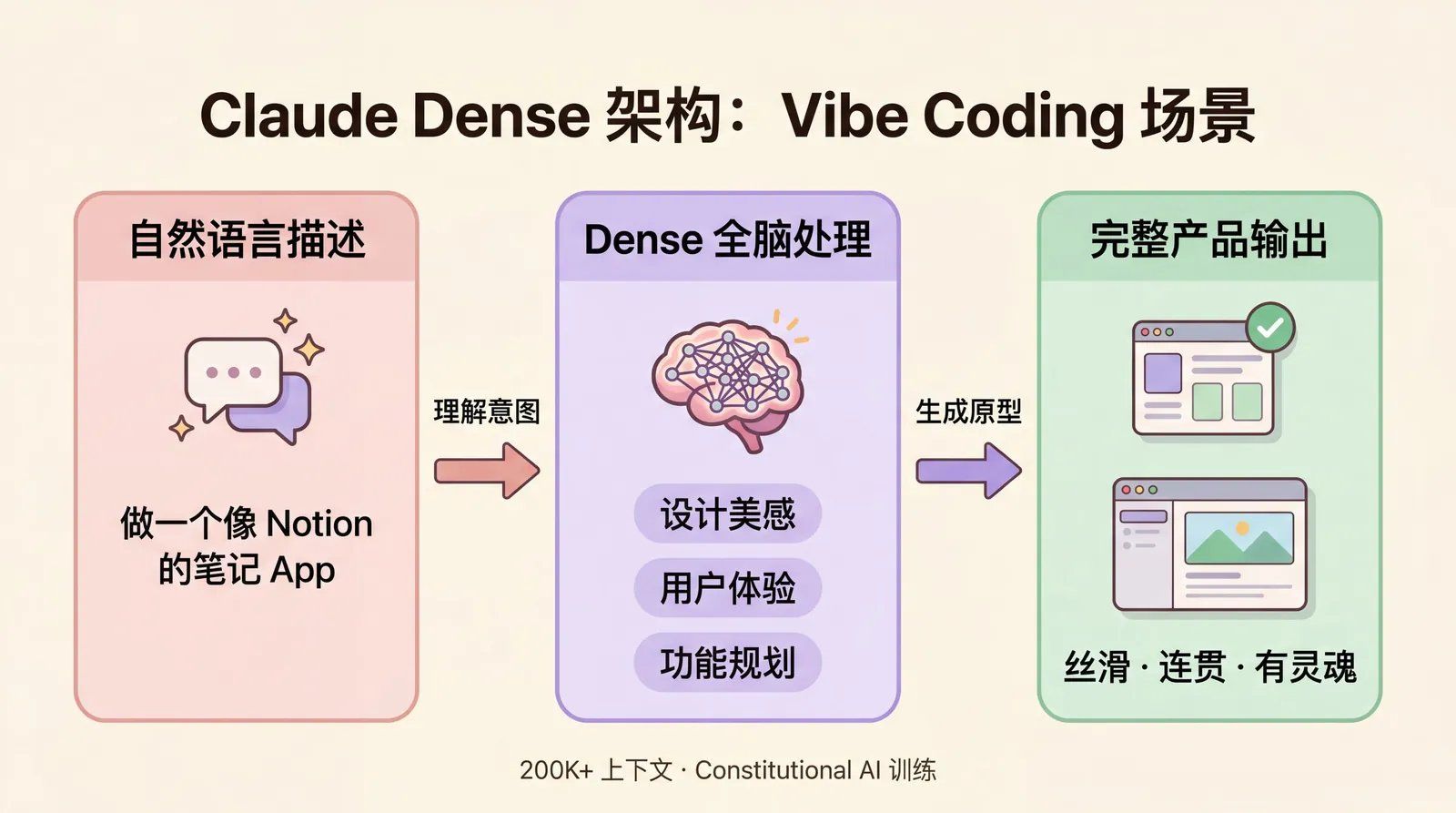
2.2 Dense 架构在此场景的天然
✓ 整体连贯性与细腻感
全参数激活确保模型对模糊提示的理解高度统一,不易出现 MoE 的路由噪声。输出不仅功能正确,还带有:
- 设计美感
- 用户体验洞察
- 主动追问:“这个 vibe 你更偏 minimalist 还是 feature-rich?”
✓ 自然语言与推理深度
Claude 的 **Constitutional AI(宪法 AI)**训练哲学强调"helpful + harmless + honest",使其像资深产品设计师。
关键特性:
- Artifacts 实时预览
- 多文件规划
- 长上下文(200K+)
✓ 社区实证
Vibe Coding 玩家(独立开发者、原型党、非传统程序员)在 Claude Code / Claude 4.6 中感受到**“聊天做产品”**的流畅感,而非单纯写代码。
2.3 为什么 MoE 在这里不够"灵魂"?
MoE 在高模糊创意任务中偶尔显得"拼凑",缺少那种"灵魂一致"的 vibe——这正是 Dense 的制胜点。
三、Codex(MoE):为什么成为传统程序员 Bug Fixing 的利器?
传统程序员在 IDE 中处理生产代码、修复 Bug、重构大项目时,核心需求是:
- 精确
- 可验证
- 快速迭代
需要定位 edge case、兼容特定库、不引入回归。
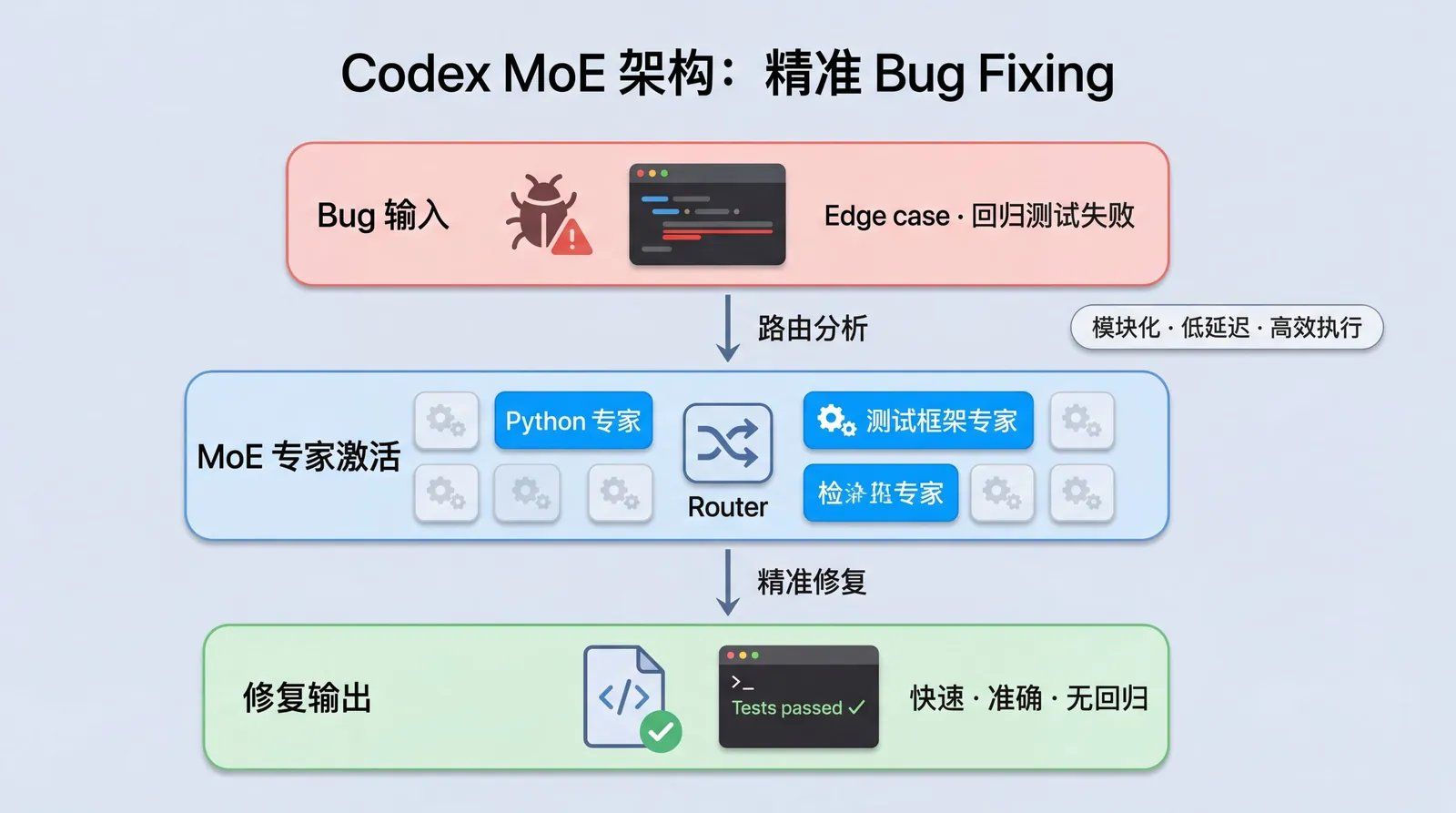
3.1 MoE 架构的模块化优势
✓ 专家专精与精准路由
不同专家可深度训练于特定领域:
- Python + PyTorch BugPython+PyTorch 错误
- 前端状态管理
- 测试框架调试
路由器看到 Bug 描述或代码片段,即激活相关专家,模块化处理能力远超 Dense 的"全脑思考"。
✓ 效率与执行力
激活参数少 → 推理更快、token 成本更低
Codex 在"set-and-forget"代理模式中表现突出:
- 读文件
- 改代码
- 跑测试
- 循环修复
尤其适合长时间自主执行。
✓ 代码训练偏好
GPT-5.x Codex 本就重度 fine-tune 于海量代码,MoE 进一步放大:
- 模式匹配
- 大规模结构化变换(如框架迁移、整个模块重构)
3.2 社区反馈
程序员常说:
“Claude 会跟你聊天,Codex 直接出活”
在真实生产环境中,Codex 的"老程序员式"精准补全与 Debug的能力更适合。
四、超越架构:训练哲学、产品设计与真实工作流
架构只是起点,更关键的是多维度因素的综合作用。
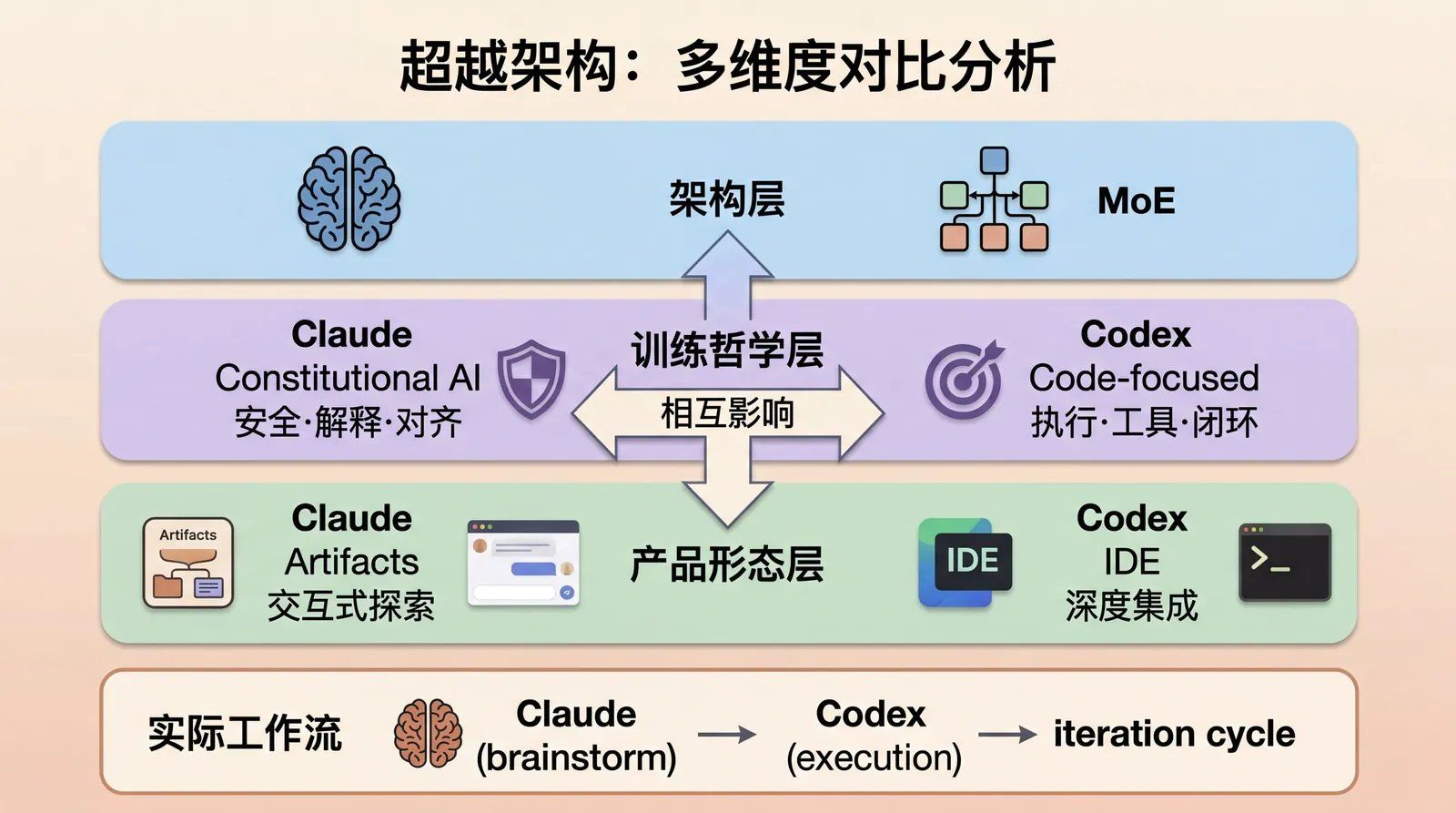
4.1 训练哲学
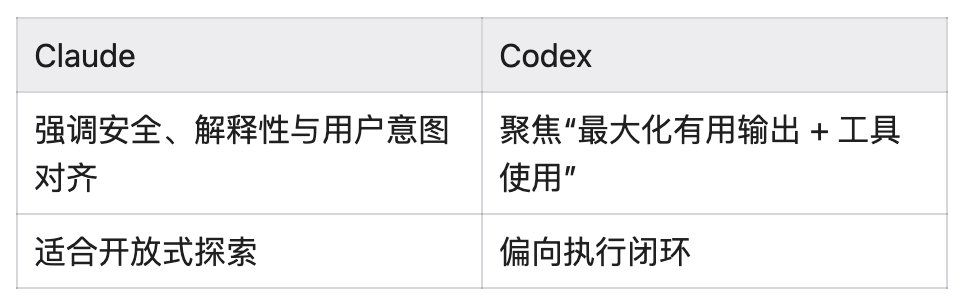
4.2 产品形态
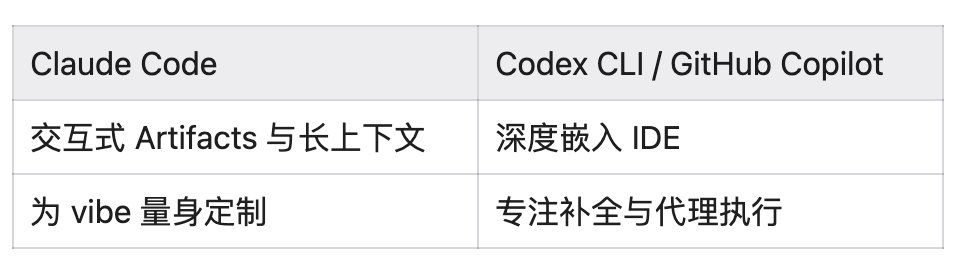
4.3 混合使用现实
多数开发者并非二选一,而是:
“vibe 脑暴用 Claude,落地执行用 Codex”
4.4 2026 年Bench 测试证实
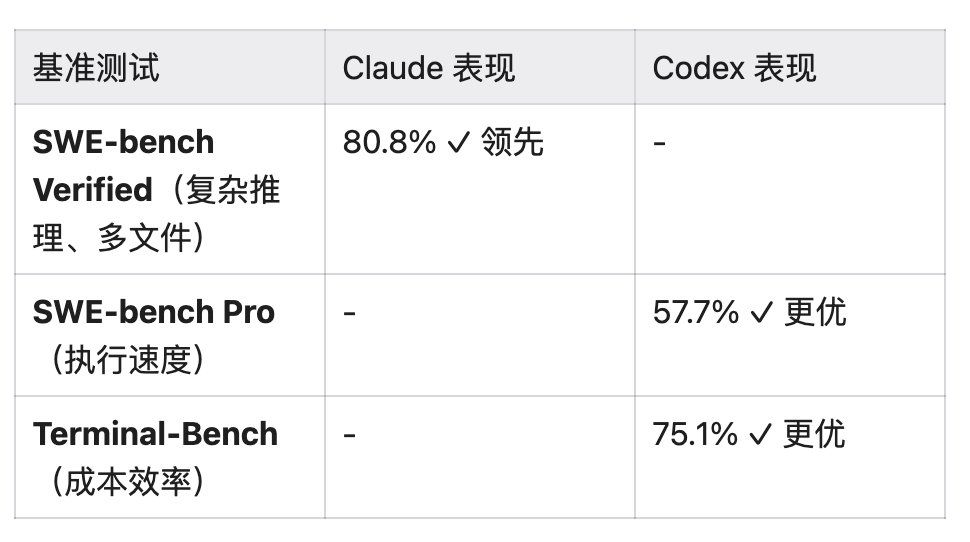
五、结论与实战建议
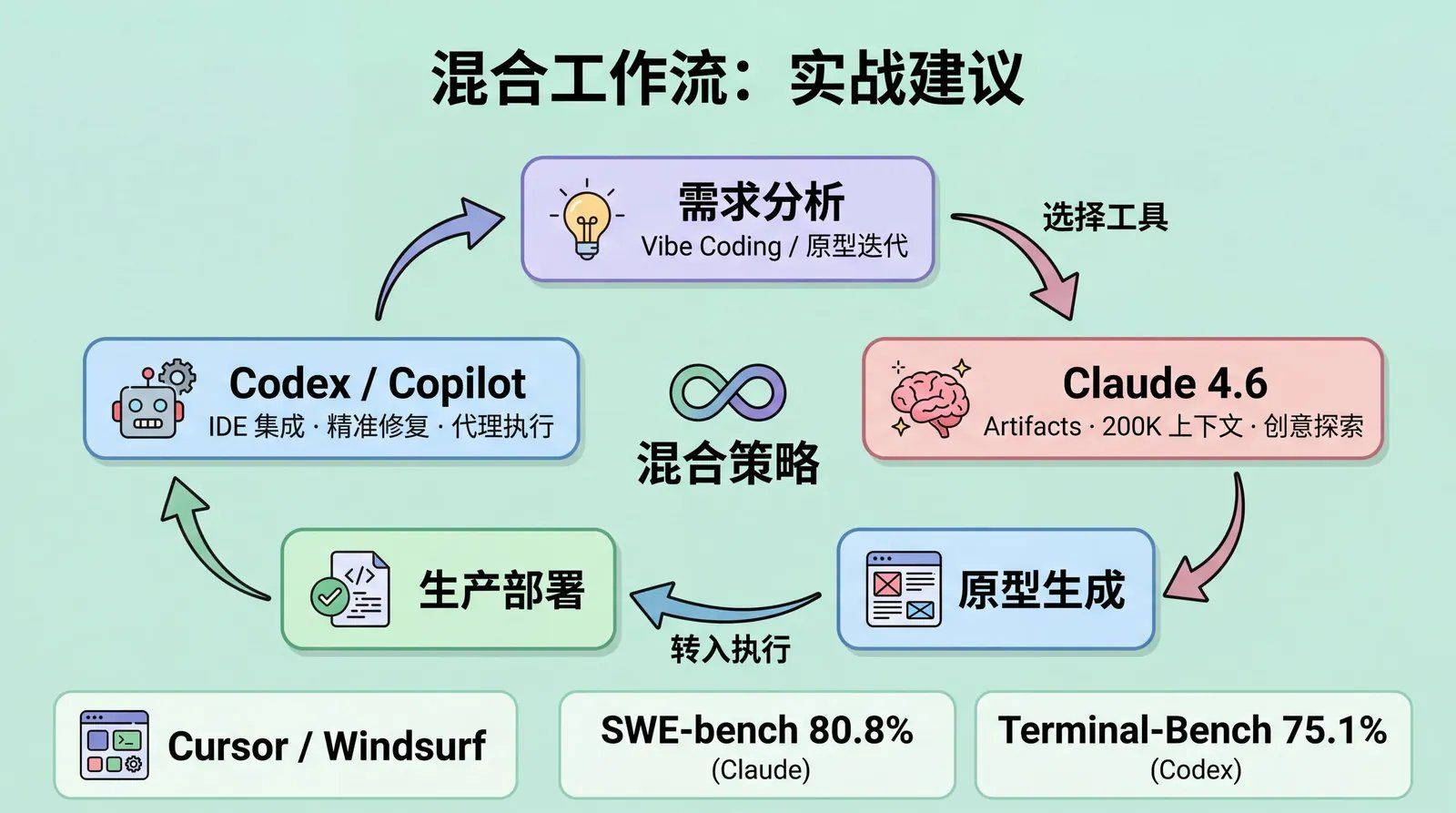
5.1 核心结论
Codex 的 MoE + 代码专精让它成为程序员"精准打击"的首选,而 Claude 的 Dense 细腻设计则让 Vibe Coding 用户感受到"懂我"的灵魂共鸣。
这一偏好差异是架构、训练、产品三维合力的结果,而非单一因素。
5.2 实战建议
场景 1:Vibe Coding / 原型迭代
→ 优先 Claude 4.6 Opus / Sonnet
- 适合:创意探索、产品原型、自然语言交互
- 工具:Claude Code、Artifacts
场景 2:生产 Bug Fixing / 大规模重构
→ 优先 GPT-5.4 Codex 或 Copilot
- 适合:精准修复、代理执行、长时程任务
- 工具:GitHub Copilot、Codex CLI
场景 3:混合工作流
→ 使用 Cursor / Windsurf 等多模型 IDE
- 结合两者优势
- Claude 负责创意和规划
- Codex 负责执行和优化
5.3 未来展望
AI 编程工具正迅速演进,未来 Hybrid MoE + Dense 混合架构或将模糊界限。
但当下,理解这些差异,能让你从"工具使用者"变成“工作流设计师”。
参考资料:
- Anthropic Claude 4 架构详解
- OpenAI GPT-5.4 与 Codex MoE 解析
- SWE-bench 官方排行榜(2026 更新)
- Karpathy Vibe Coding 讨论
- 社区对比实测
作者:Berryxia.AI
交流:358848136