引言
Transformer 架构已经成为自然语言处理、计算机视觉等领域的基础模型。然而,其核心组件——自注意力机制(Self-Attention)的时间和空间复杂度都是 $O(N^2)$,其中 $N$ 是序列长度。这种二次方复杂度严重限制了模型处理长序列的能力。
FlashAttention 是由斯坦福大学 Tri Dao 等人提出的一种革命性算法,通过深入理解 GPU 内存层级结构,实现了精确注意力计算的显著加速,同时大幅降低内存占用。
论文链接:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
PDF(本地):FlashAttention_Conquering_the_Memory_Wall.pdf
音频
核心问题:GPU 内存层级与 IO 瓶颈
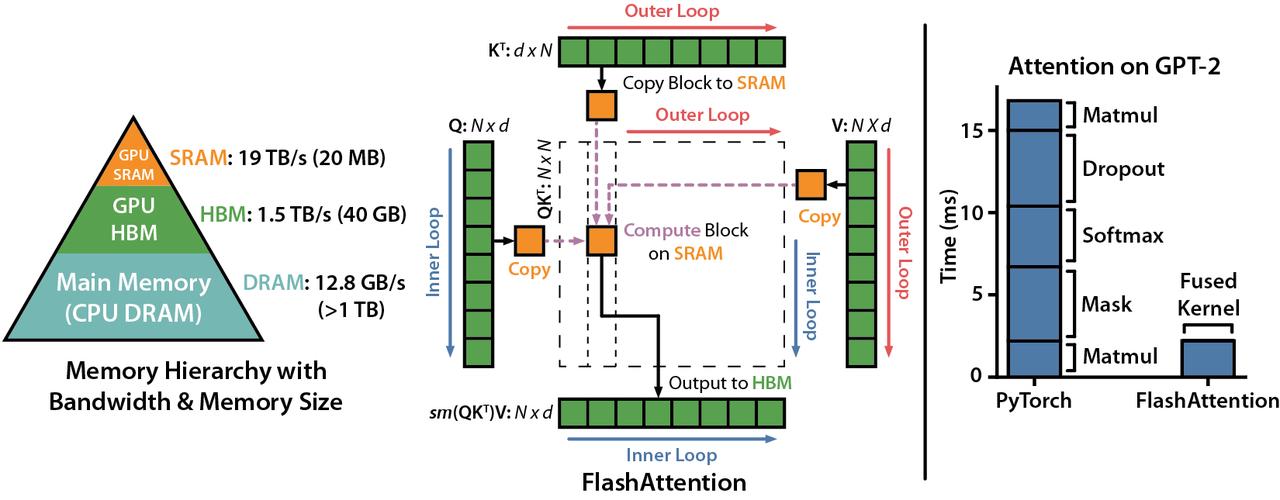
GPU 内存架构
现代 GPU 具有复杂的内存层级结构:
| 内存类型 | 容量 | 带宽 | 延迟 |
|---|---|---|---|
| SRAM(片上共享内存) | ~20MB | ~19 TB/s | 极低 |
| HBM(高带宽内存) | 40-80GB | 1.5-2 TB/s | 较高 |
传统注意力实现的问题在于:计算速度远快于内存读写速度。GPU 大部分时间都在等待数据从 HBM 传输到 SRAM,而不是在进行实际计算。
标准注意力的 IO 开销
标准自注意力的计算流程:
这个过程中,中间结果 $S$ 和 $P$ 都是 $N \times N$ 的大矩阵,需要反复在 HBM 和 SRAM 之间传输,造成巨大的 IO 开销。
FlashAttention 核心算法
关键洞察
FlashAttention 的核心思想是:通过分块计算(Tiling)和重计算(Recomputation),避免将完整的 $N \times N$ 注意力矩阵写入 HBM。
分块 Softmax 算法
标准 softmax 需要知道所有元素才能计算归一化因子。FlashAttention 使用了一个巧妙的在线 softmax 算法:
对于向量 $x = [x_1, x_2, …, x_n]$,softmax 可以增量计算:
$$m^{(j)} = \max(m^{(j-1)}, x_j)$$
$$\ell^{(j)} = e^{m^{(j-1)} - m^{(j)}} \ell^{(j-1)} + e^{x_j - m^{(j)}}$$
$$o^{(j)} = e^{m^{(j-1)} - m^{(j)}} o^{(j-1)} + e^{x_j - m^{(j)}} v_j$$
最终结果:$o = o^{(n)} / \ell^{(n)}$
算法流程
| |
IO 复杂度分析
| 方法 | HBM 访问次数 | 内存占用 |
|---|---|---|
| 标准注意力 | $O(N^2 d + N^2)$ | $O(N^2)$ |
| FlashAttention | $O(N^2 d^2 / M)$ | $O(N)$ |
其中 $M$ 是 SRAM 大小,$d$ 是注意力头维度。当 $M > d^2$ 时(通常成立),FlashAttention 的 IO 复杂度接近最优。
反向传播:重计算策略
传统方法的问题
标准反向传播需要保存前向传播中的 $S$ 和 $P$ 矩阵,内存占用 $O(N^2)$。
FlashAttention 的解决方案
FlashAttention 在反向传播时重新计算 $S$ 和 $P$,而不是从内存中读取:
- 保存输出 $O$ 和 logsumexp 值 $L$
- 反向传播时重新计算 $S = QK^T$
- 使用保存的 $L$ 重建 $P = \text{softmax}(S)$
- 计算梯度
虽然增加了 FLOPs,但由于减少了 IO,整体速度反而更快。这体现了一个重要原则:在 IO 密集型场景下,用计算换 IO 是划算的。
FlashAttention-2 改进
FlashAttention-2 在原版基础上做了进一步优化:
1. 减少非矩阵乘法操作
将更多操作融合到矩阵乘法中,更好地利用 Tensor Core。
2. 改进并行策略
- 序列并行:沿序列长度维度并行
- 批次并行:沿批次维度并行
- 头并行:沿注意力头维度并行
3. 更优的工作分配
根据不同 GPU 架构(A100、H100)调整块大小和线程分配。
性能对比
| GPU | 标准注意力 | FlashAttention | FlashAttention-2 |
|---|---|---|---|
| A100 | 基准 | 2.4x | 3.5x |
| H100 | 基准 | 2.8x | 4.2x |
FlashAttention-3:面向 Hopper 架构
FlashAttention-3 针对 NVIDIA Hopper 架构(H100)进行了深度优化:
异步执行
利用 Hopper 的 TMA(Tensor Memory Accelerator)实现:
- 数据加载与计算重叠
- 异步 warp 调度
FP8 支持
支持 FP8 精度,在保持精度的同时进一步提升吞吐量。
性能数据
在 H100 上,FlashAttention-3 实现了接近理论峰值的性能:
- FP16:约 740 TFLOPs(理论峰值 989 TFLOPs)
- FP8:约 1.2 PFLOPs
应用场景与影响
长上下文模型
FlashAttention 使得训练和推理超长序列成为可能:
| 模型 | 原始上下文 | 使用 FlashAttention |
|---|---|---|
| GPT-4 | 8K | 128K |
| Claude | 8K | 200K |
| Gemini | - | 1M+ |
主流框架集成
FlashAttention 已被广泛集成:
- PyTorch:
torch.nn.functional.scaled_dot_product_attention - Hugging Face Transformers: 默认启用
- vLLM: 推理优化
- DeepSpeed: 分布式训练
代码示例
| |
相关工作与扩展
Memory Efficient Attention
Google 的 Memory Efficient Attention 采用类似的分块思想,但实现细节不同。
PagedAttention
vLLM 提出的 PagedAttention 将 KV Cache 分页管理,与 FlashAttention 结合使用效果更佳。
Ring Attention
将 FlashAttention 扩展到分布式场景,通过环形通信实现跨设备的长序列注意力。
Multi-Query/Grouped-Query Attention
FlashAttention 完美支持 MQA 和 GQA,进一步减少 KV Cache 内存占用。
技术启示
1. IO 感知算法设计
FlashAttention 的成功证明:理解硬件特性是优化算法的关键。在 GPU 上,内存带宽往往是瓶颈,而非计算能力。
2. 计算换内存
在某些场景下,重新计算比存储更高效。这挑战了传统的"空间换时间"思维。
3. 精确 vs 近似
FlashAttention 证明:通过算法创新,可以实现精确计算的高效实现,不必牺牲精度。
学习建议
理论基础
- 深入理解 GPU 内存架构(HBM、SRAM、Cache/Shared Memory 层级)
- 掌握标准注意力的计算流程与 IO 瓶颈定位方法
- 学习 IO 复杂度分析与“算力换 IO”的优化思路
实践路径
- 对照阅读论文与官方实现,理解 tiling、online softmax、kernel fusion 的对应关系
- 在 PyTorch 中实现一个简化版分块 attention(先不追求极致性能)
- 将实现与
torch.nn.functional.scaled_dot_product_attention的行为做一致性对比
扩展方向
- 阅读 FlashAttention-2 的并行与工作划分改动,理解为什么更快
- 结合 vLLM / PagedAttention 理解推理侧 KV Cache 的系统优化
- 了解 ring attention 等分布式长上下文方案与通信代价
总结
FlashAttention 是一个里程碑式的工作,它:
- 解决了注意力机制的 IO 瓶颈:通过分块计算和重计算策略
- 实现了显著的性能提升:2-4 倍加速,内存减少 5-20 倍
- 使长上下文成为可能:推动了 GPT-4、Claude 等模型的发展
- 改变了算法设计思维:强调 IO 感知的重要性
FlashAttention 的核心贡献不仅是一个高效的注意力实现,更是一种从硬件角度思考算法设计的方法论。这种思维方式对于未来 AI 系统的优化具有深远影响。